Randomized Multi-Head Attention#
Embedding dimension 128 — ReLU activation#
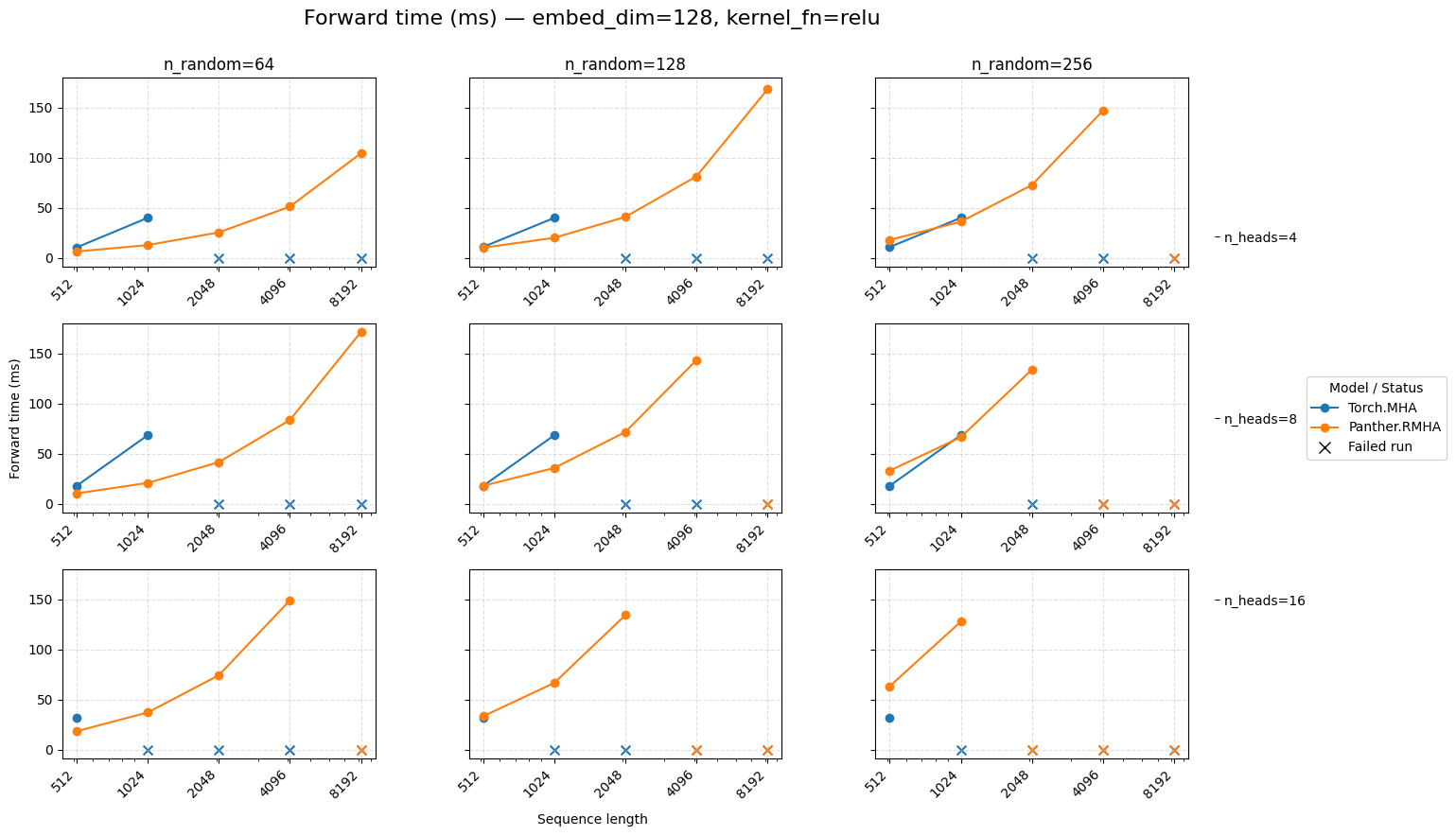
Forward time for attention embed=128 ReLU
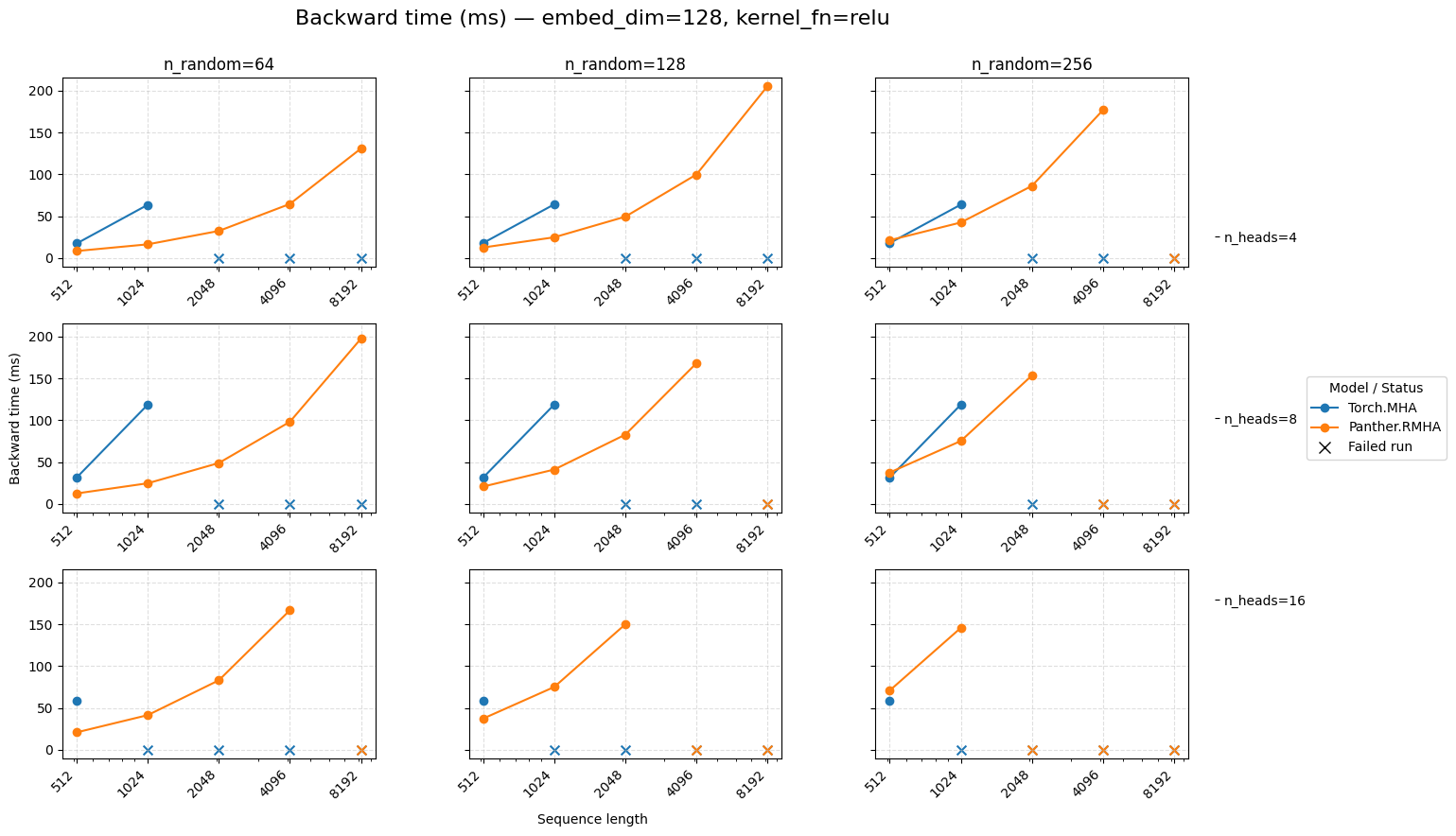
Backward time for attention embed=128 ReLU
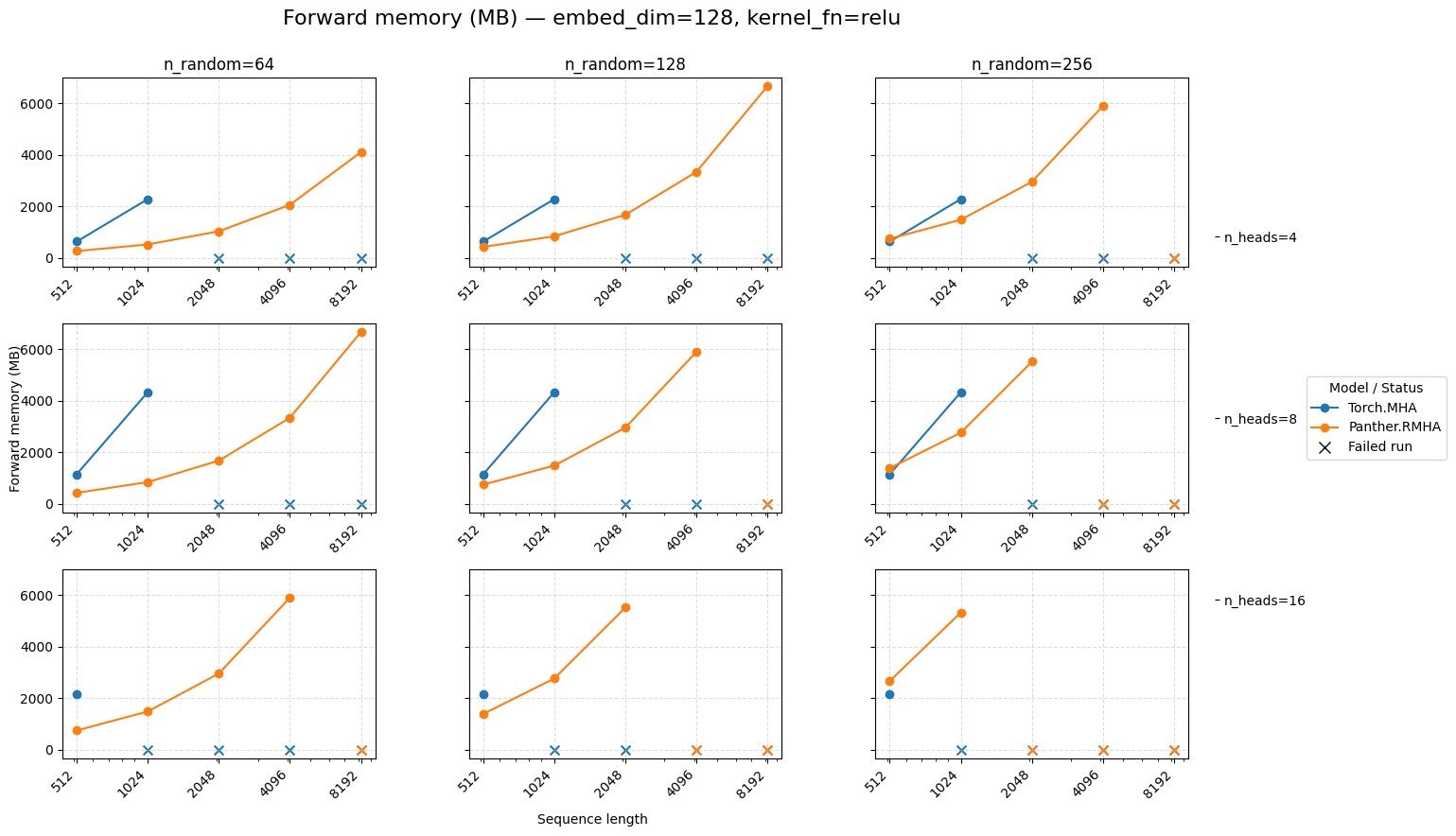
Forward memory for attention embed=128 ReLU
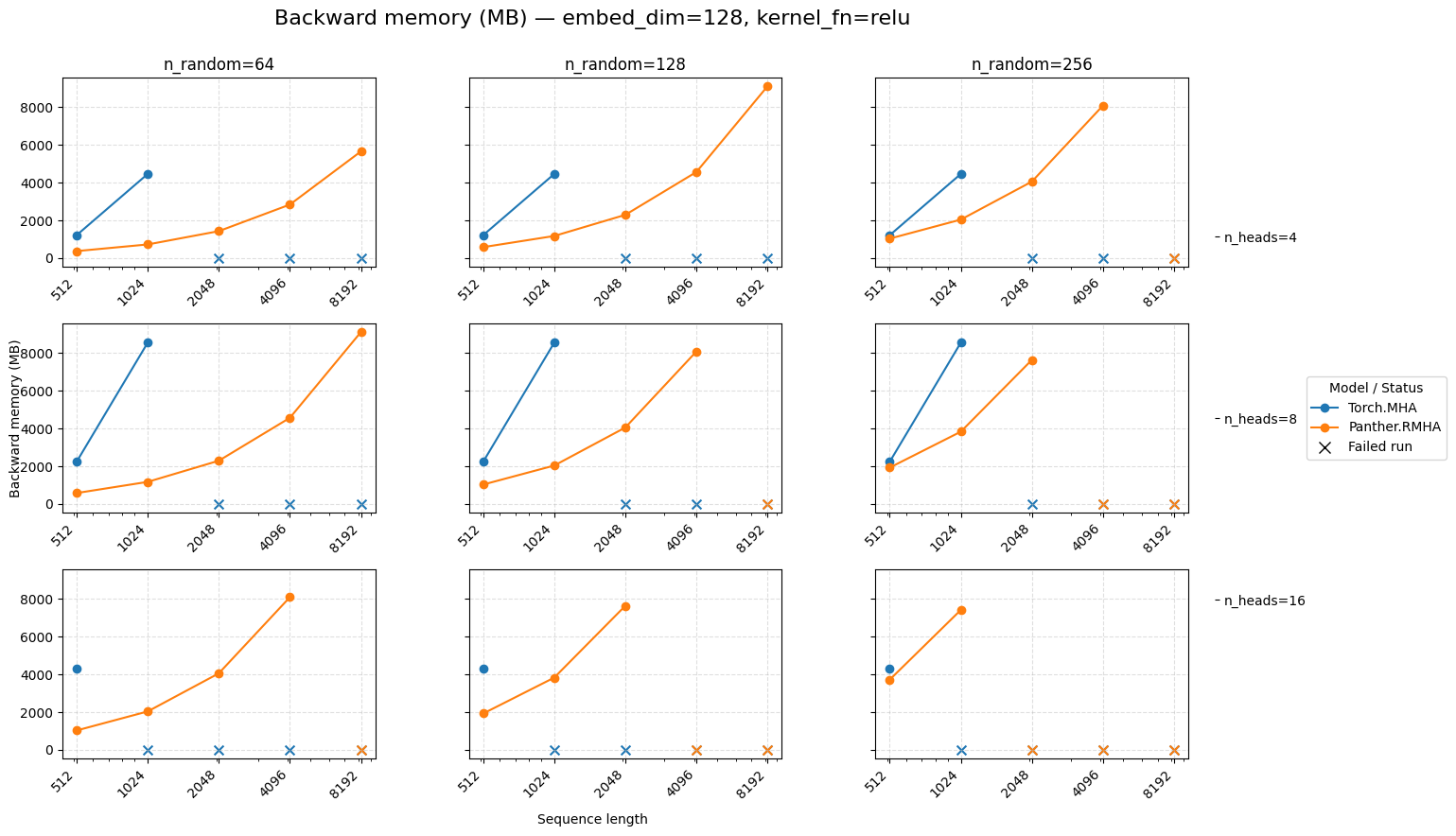
Backward memory for attention embed=128 ReLU
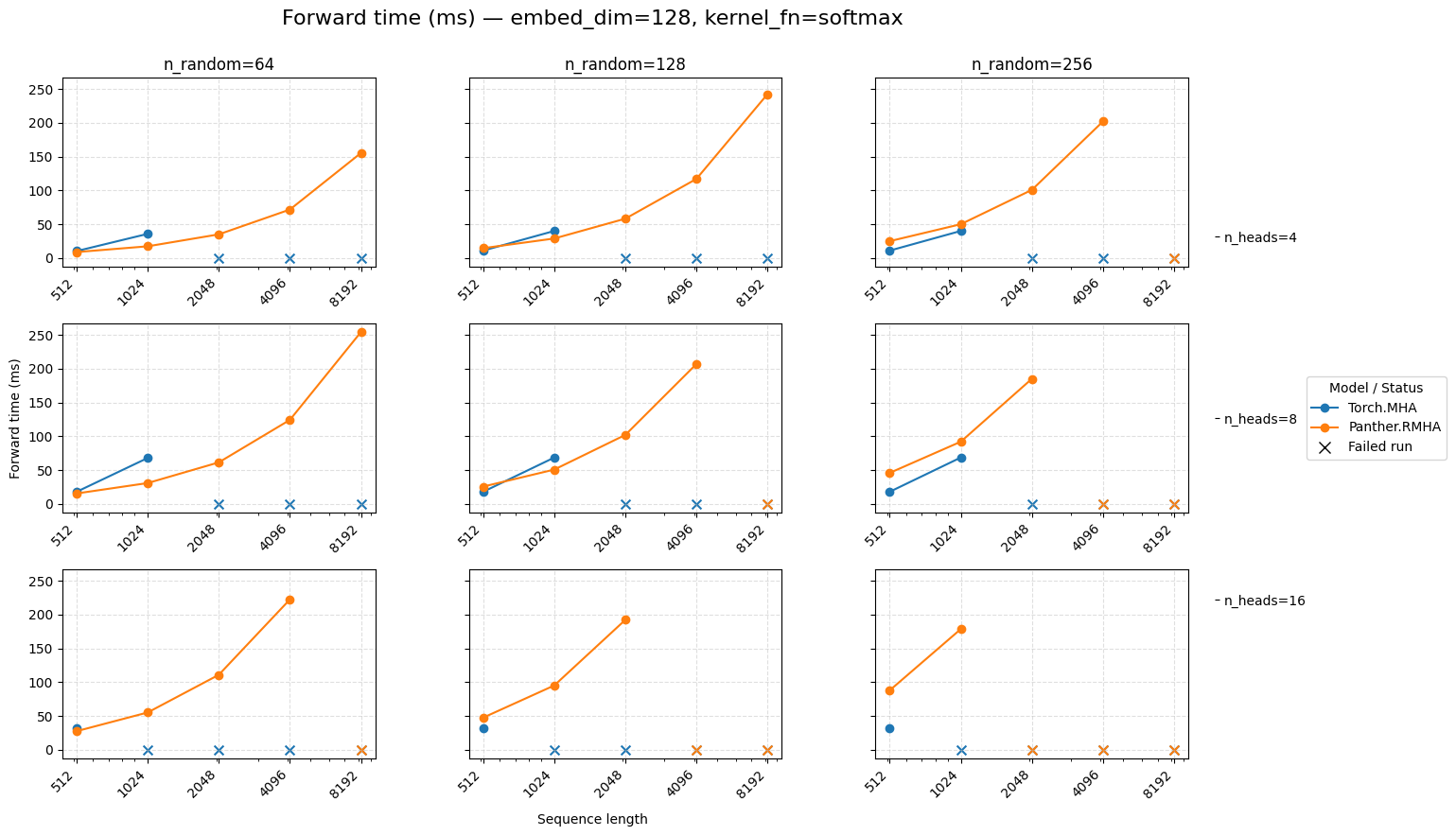
Embedding dimension 128 — Softmax activation#
Forward time for attention embed=128 Softmax
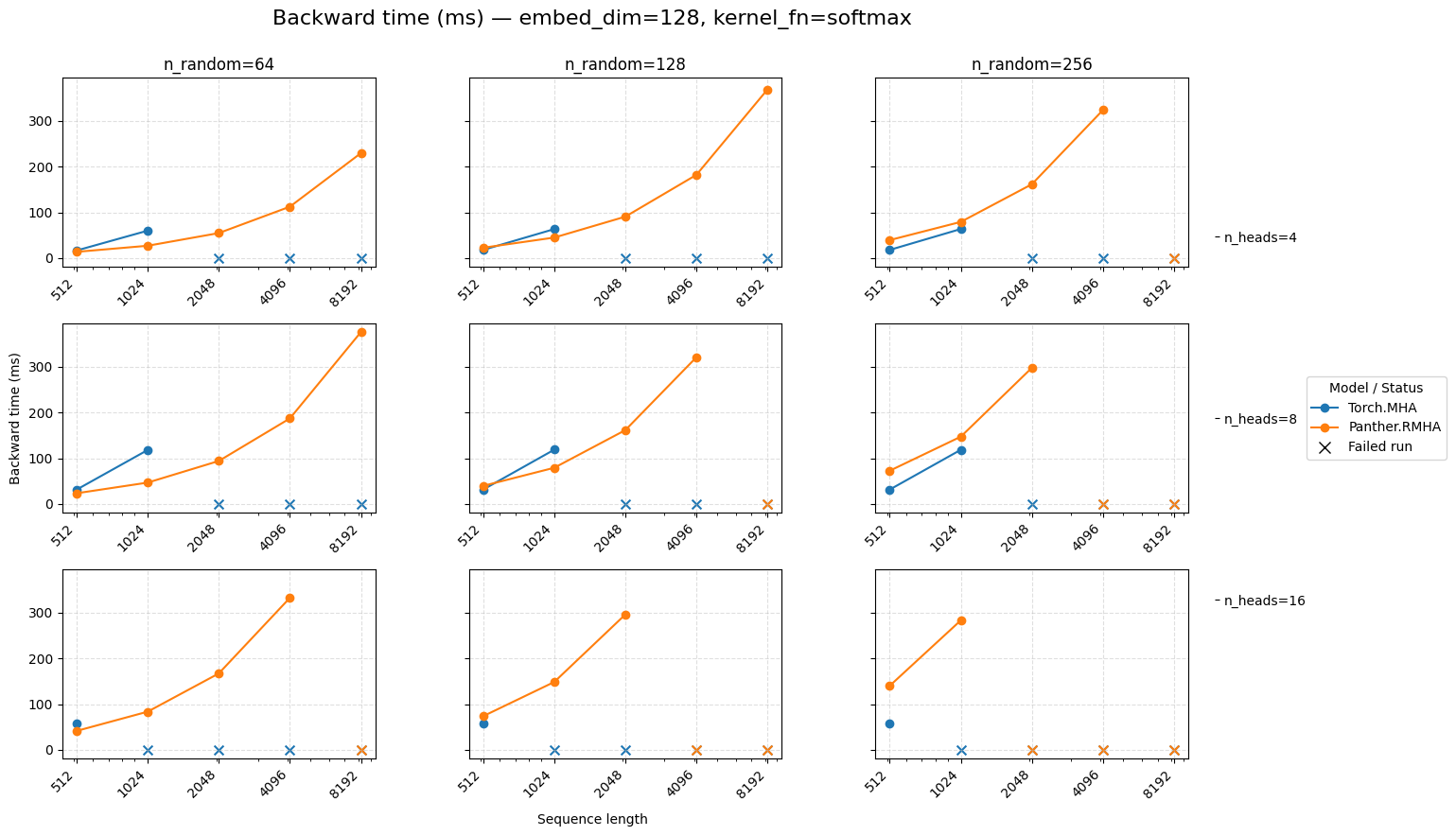
Backward time for attention embed=128 Softmax
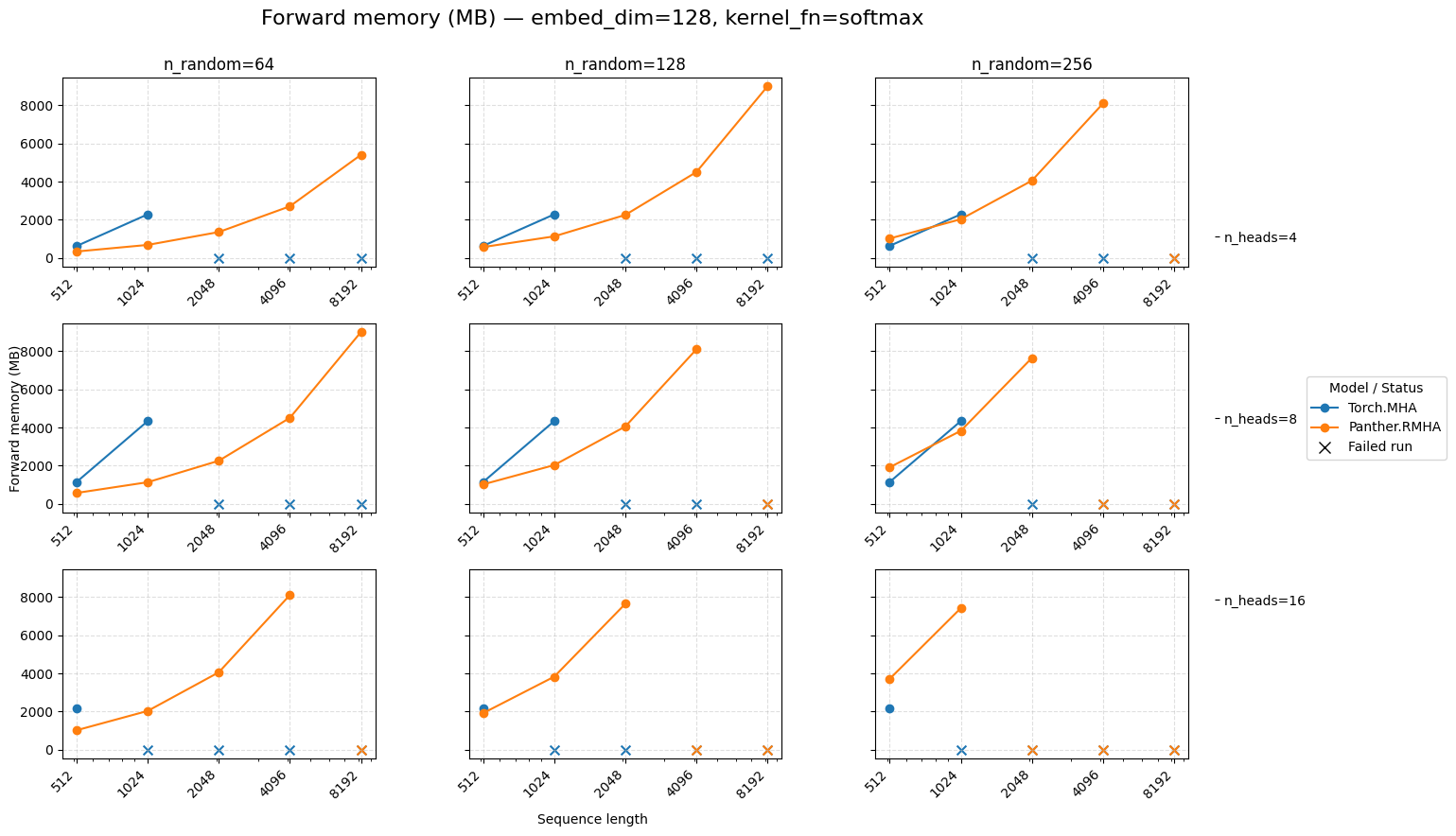
Forward memory for attention embed=128 Softmax
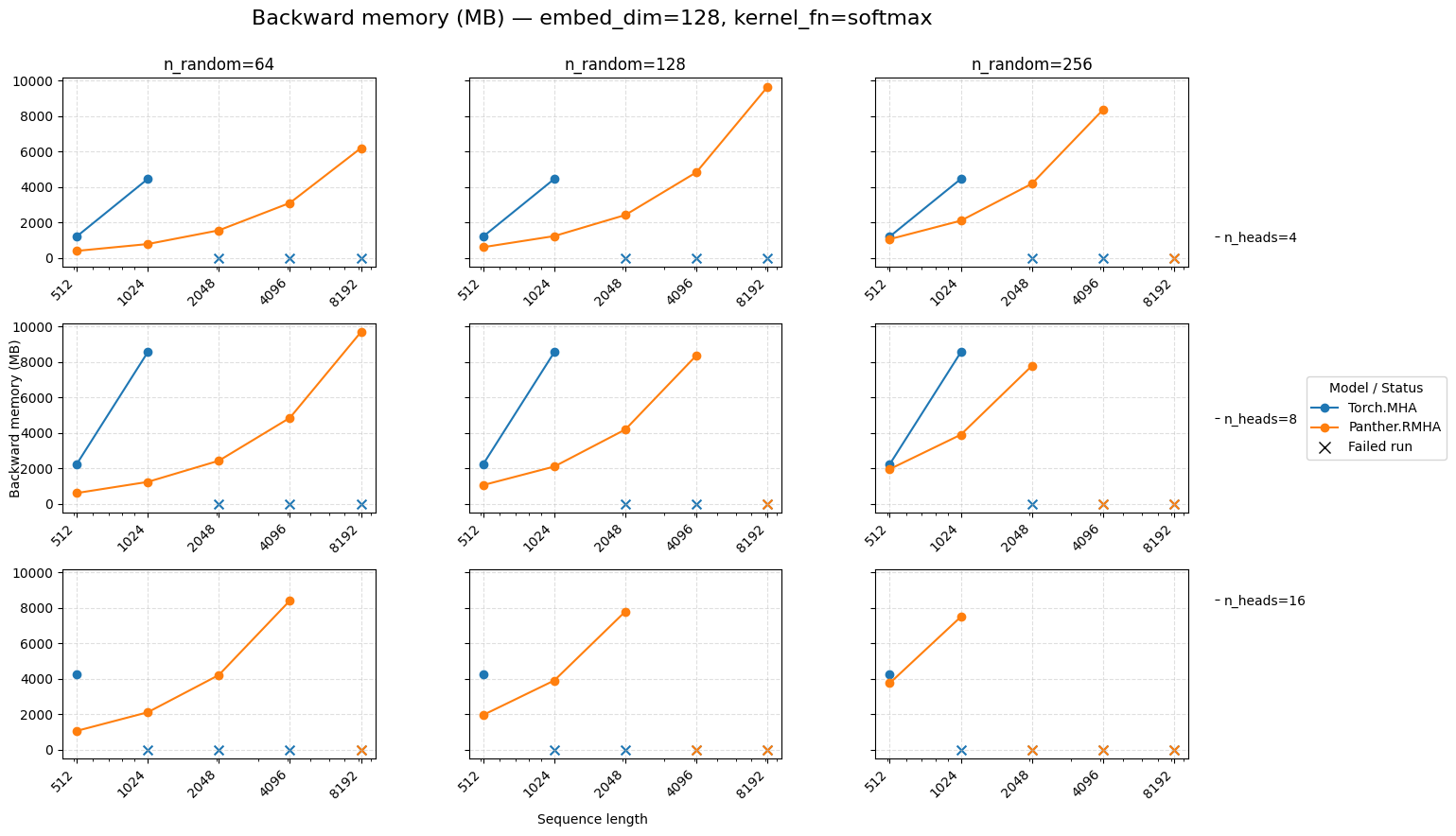
Backward memory for attention embed=128 Softmax
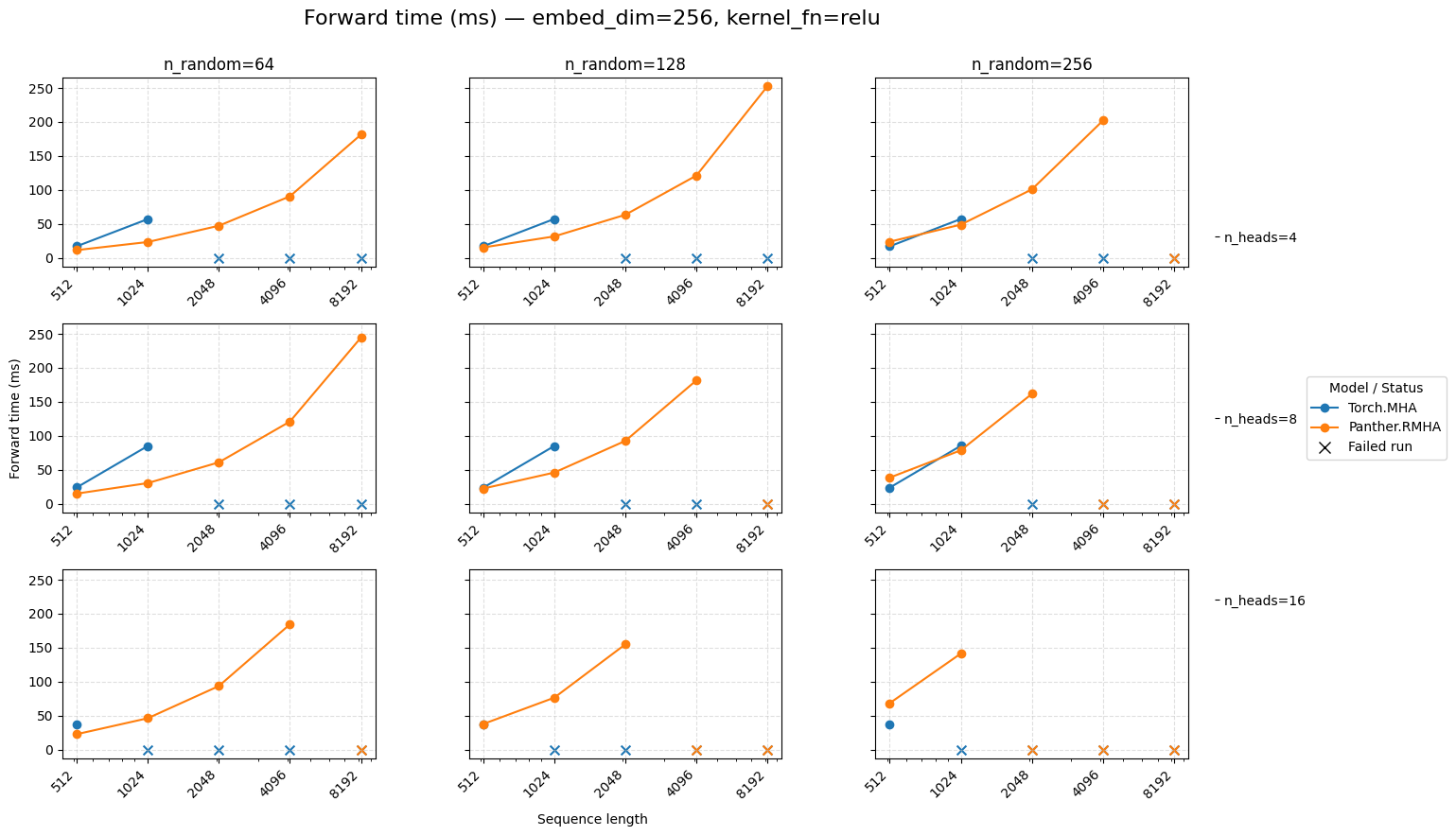
Embedding dimension 256 — ReLU activation#
Forward time for attention embed=256 ReLU
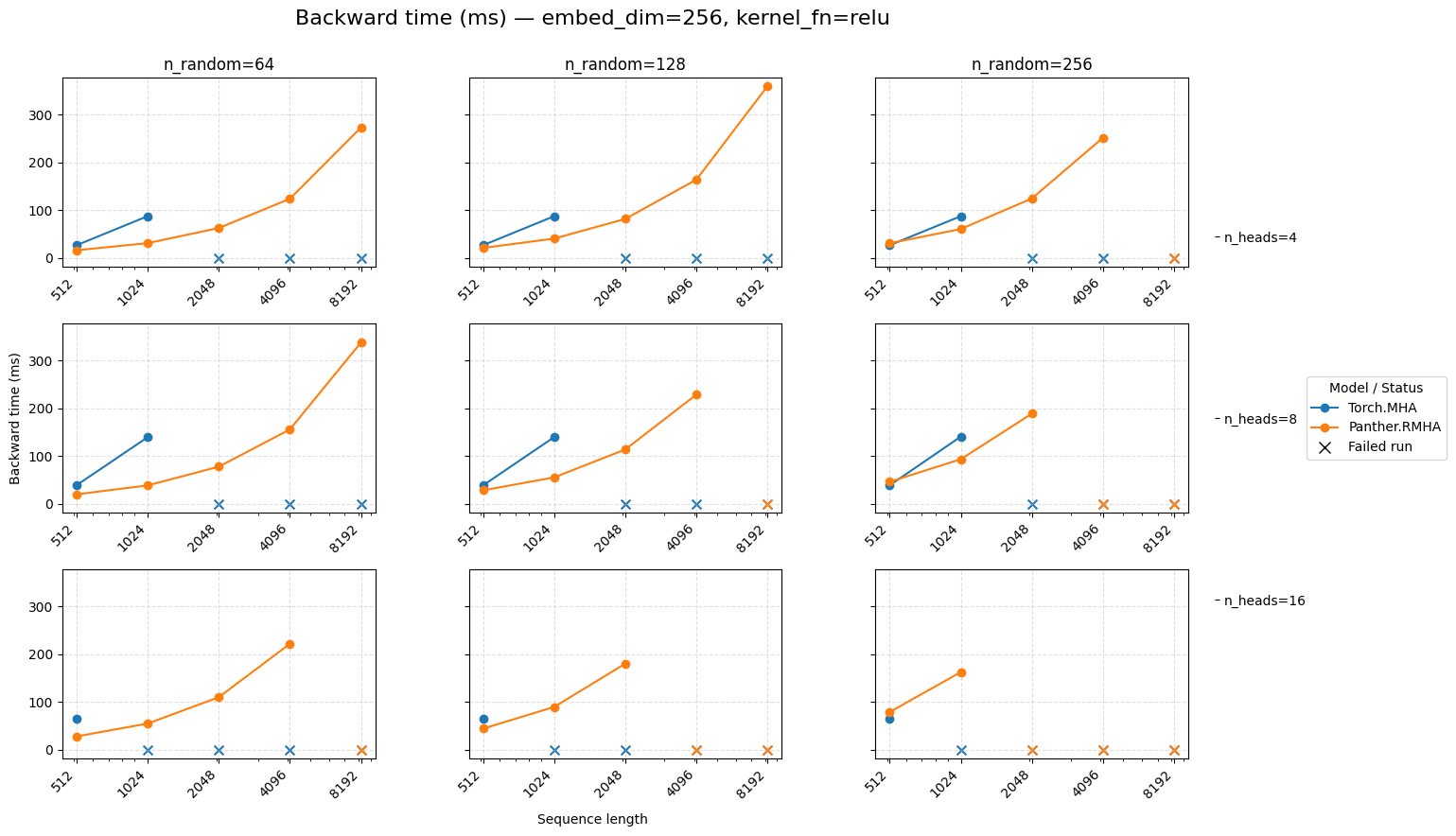
Backward time for attention embed=256 ReLU
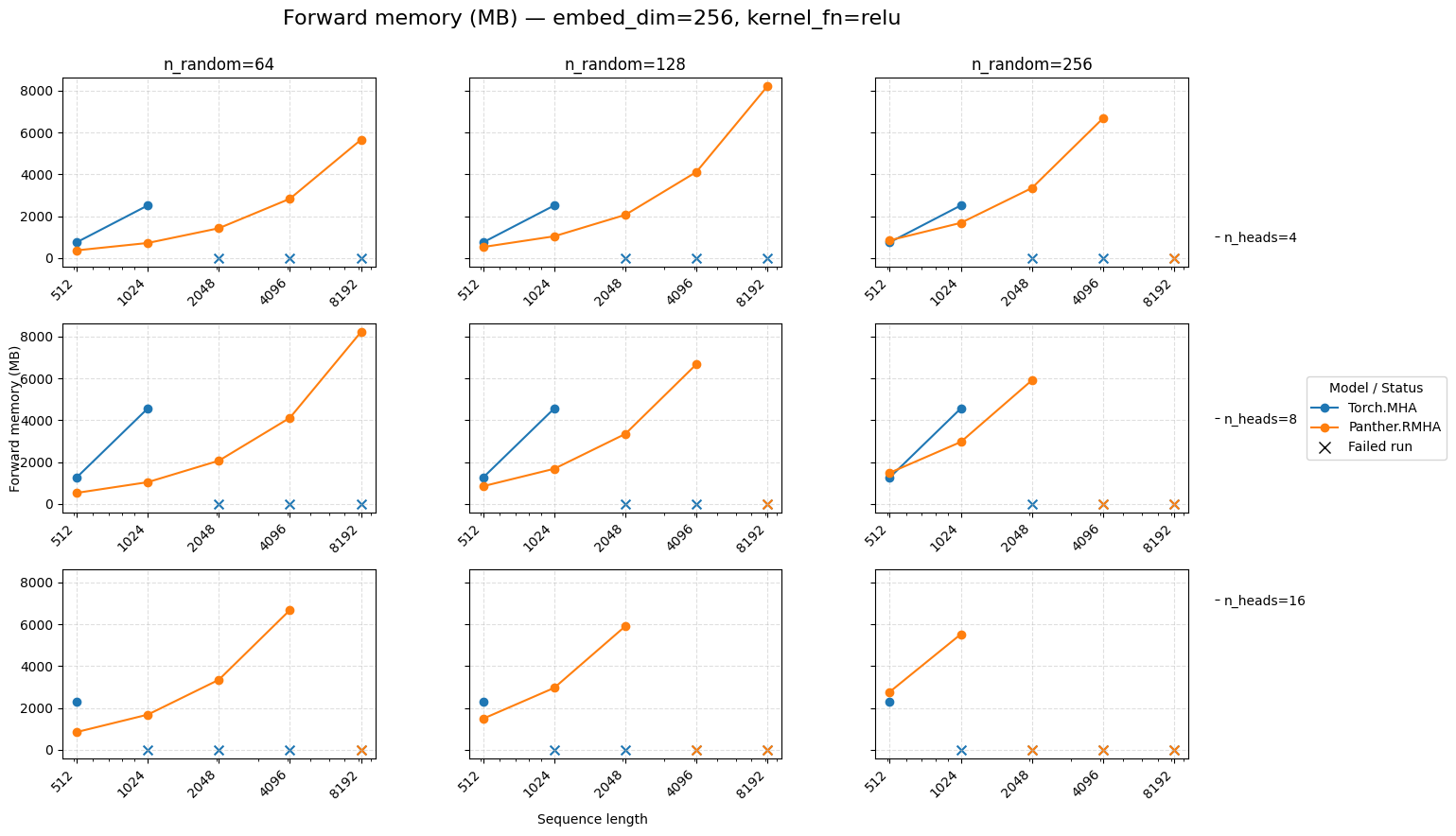
Forward memory for attention embed=256 ReLU
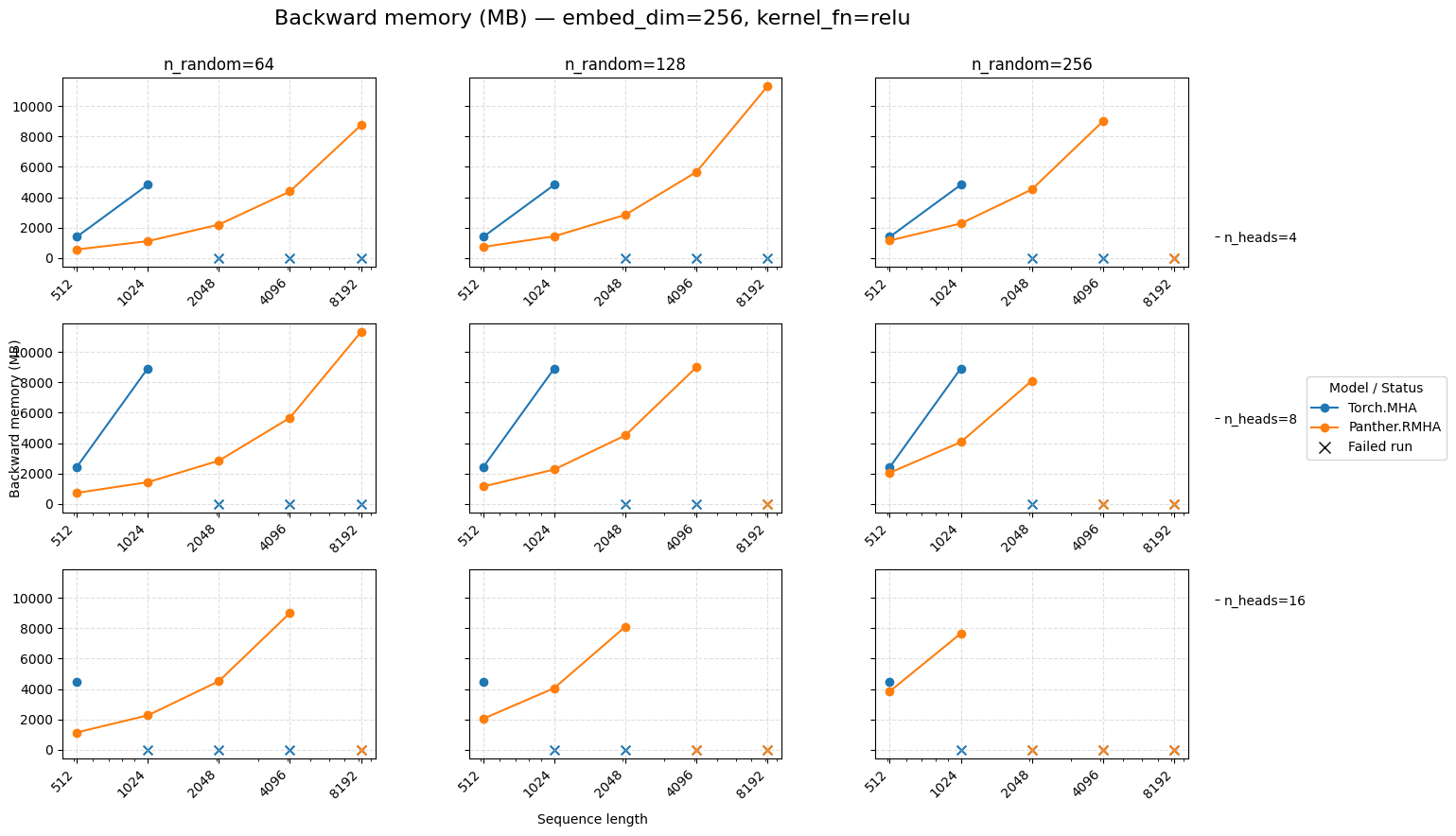
Backward memory for attention embed=256 ReLU
Embedding dimension 256 — Softmax activation#
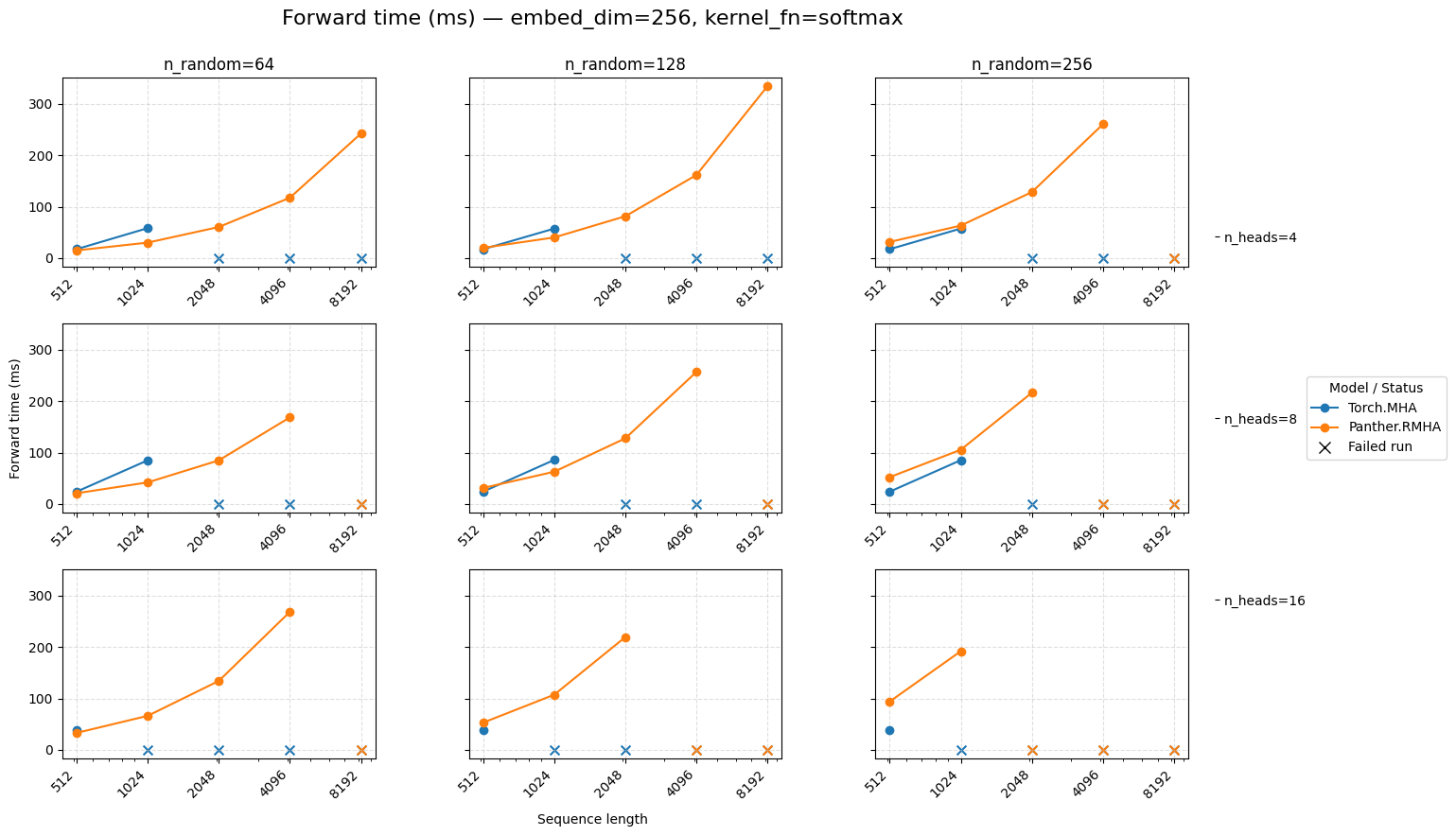
Forward time for attention embed=256 Softmax
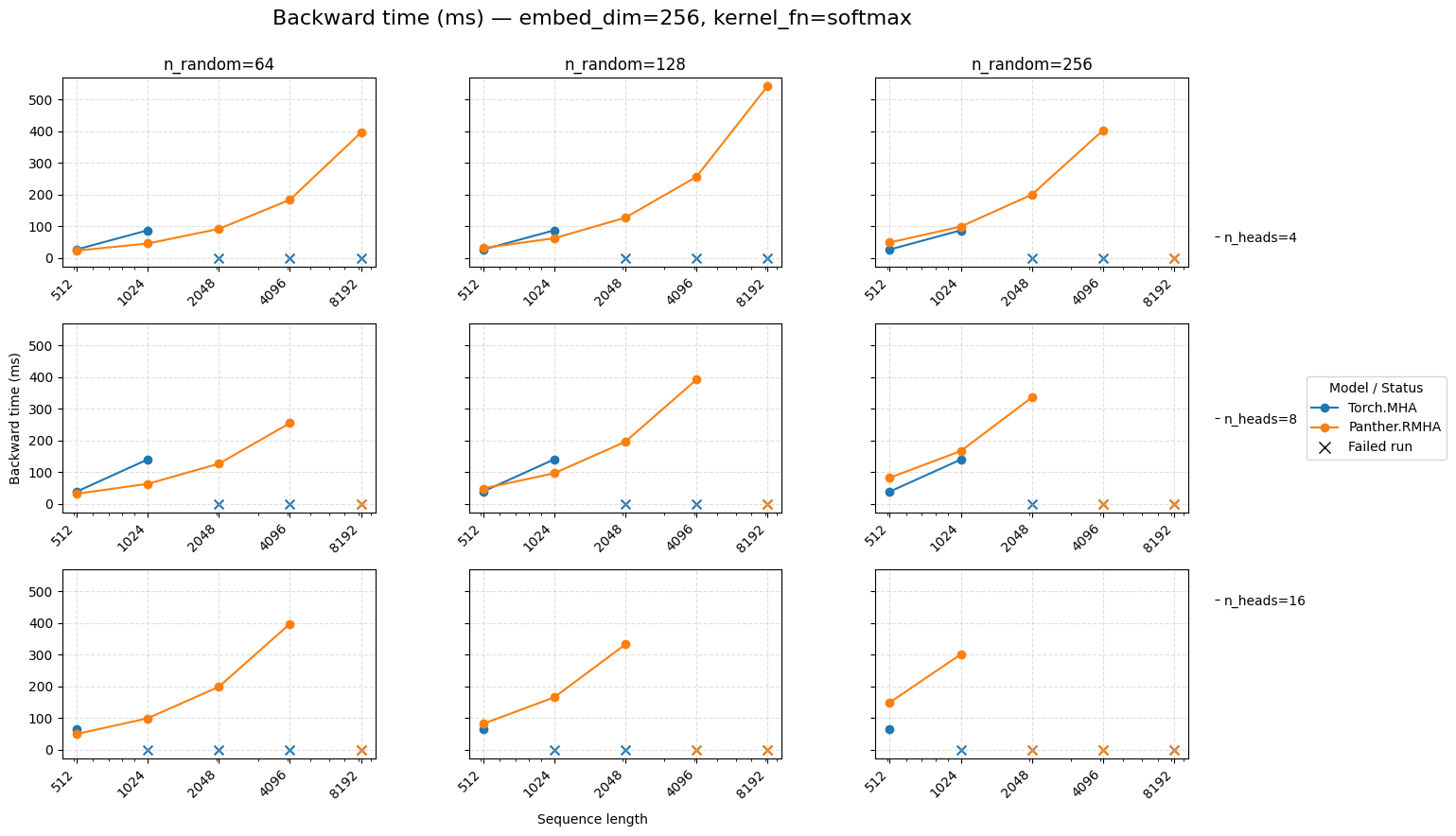
Backward time for attention embed=256 Softmax
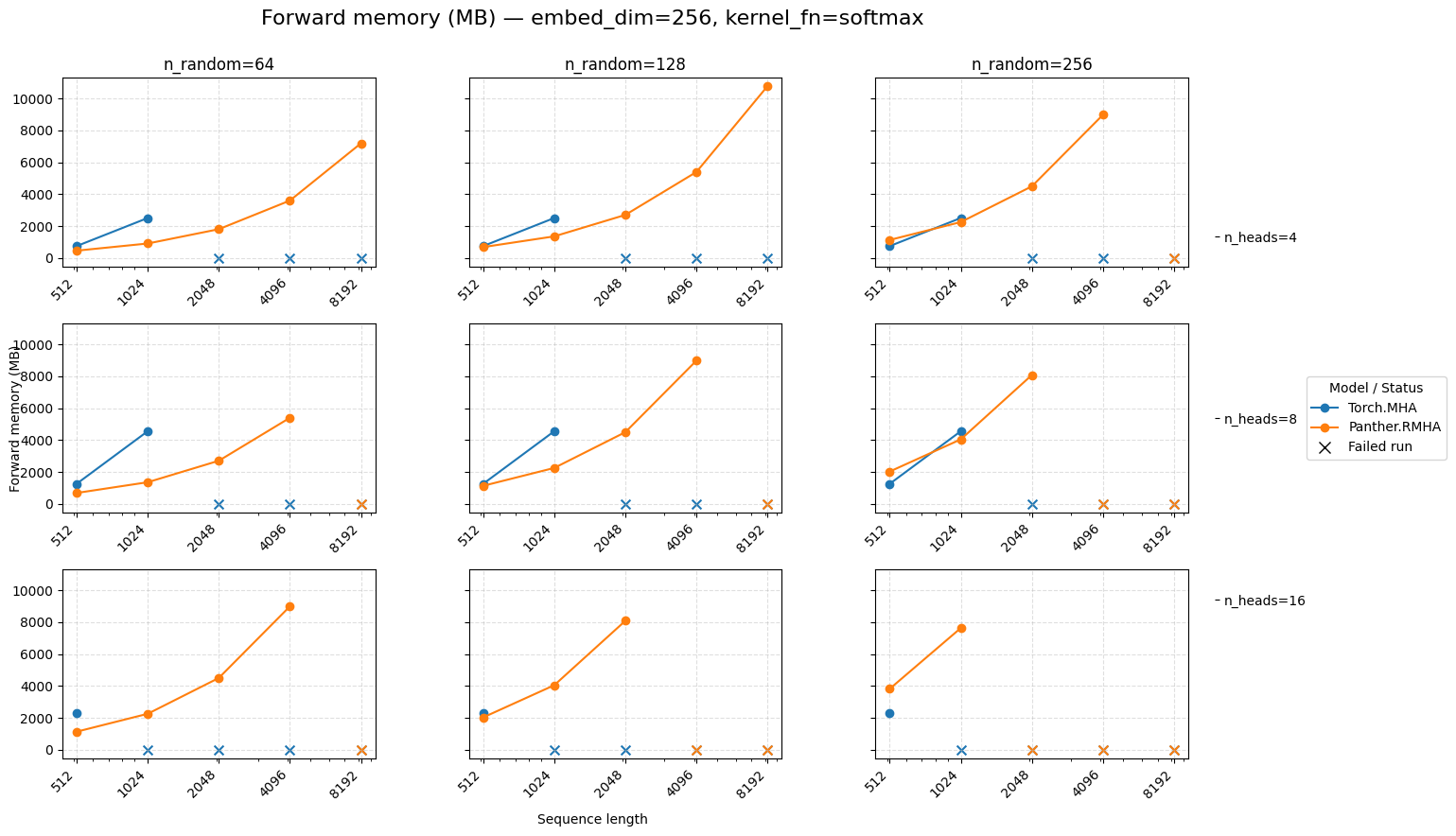
Forward memory for attention embed=256 Softmax
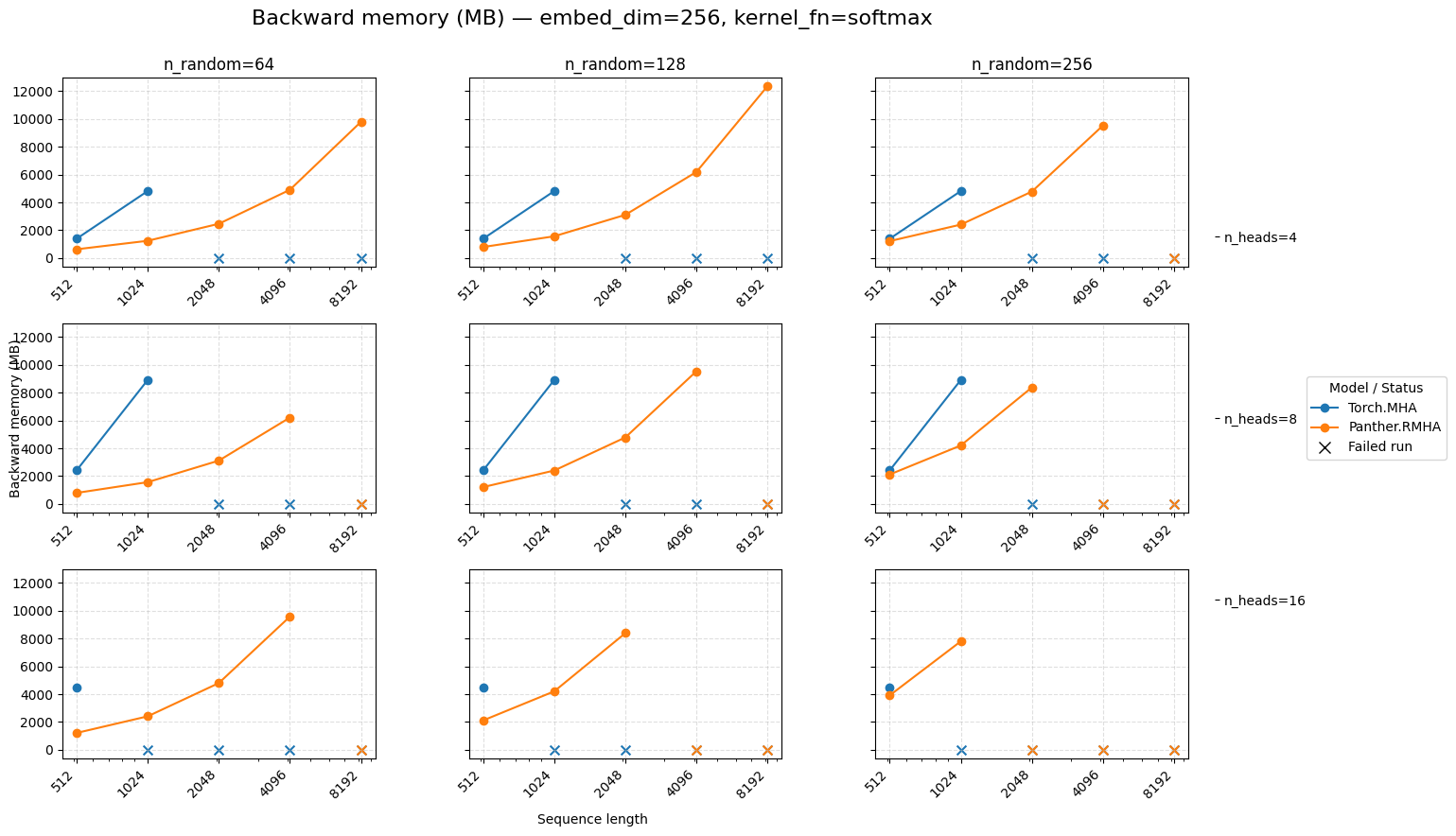
Backward memory for attention embed=256 Softmax
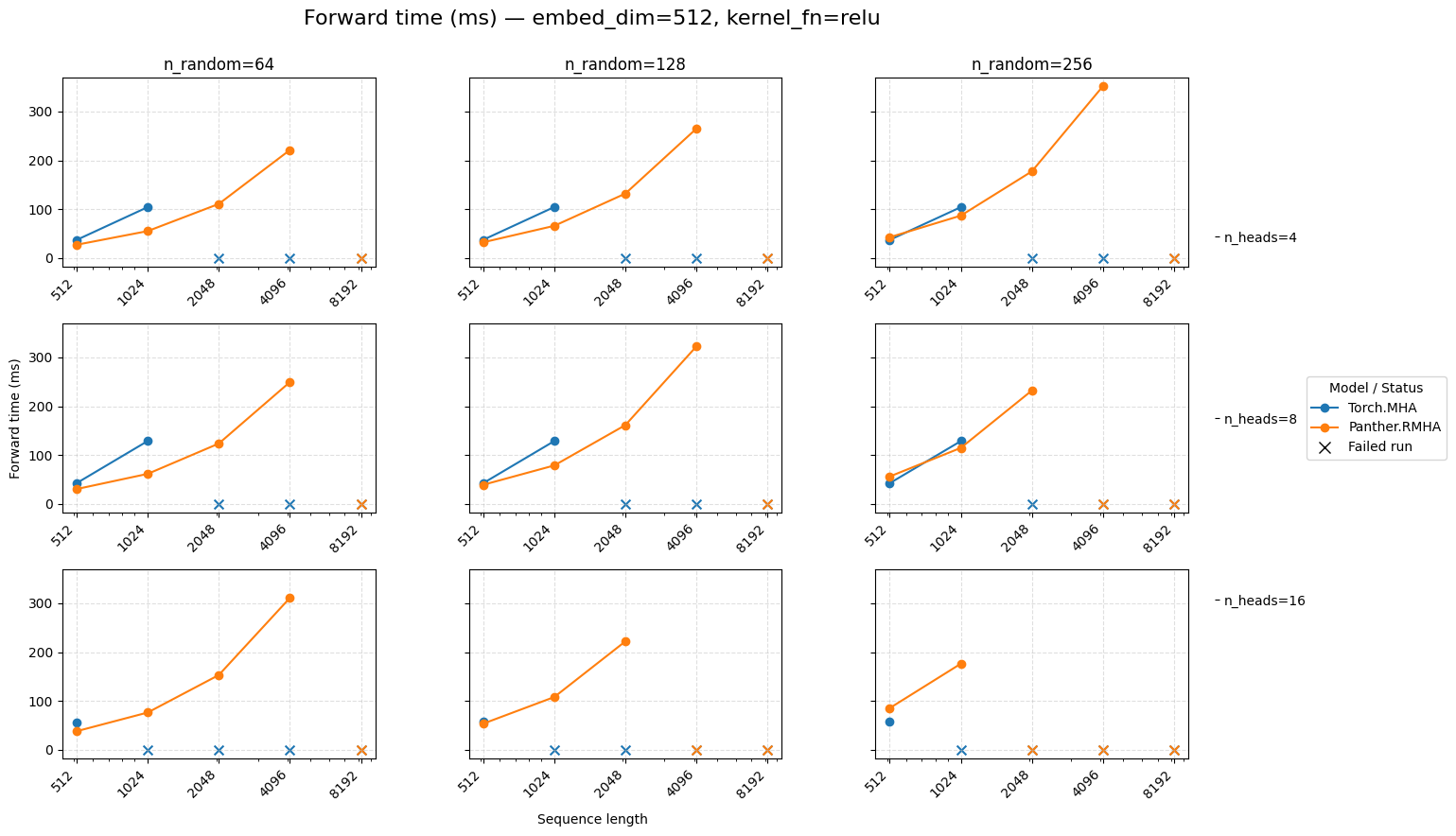
Embedding dimension 512 — ReLU activation#
Forward time for attention embed=512 ReLU
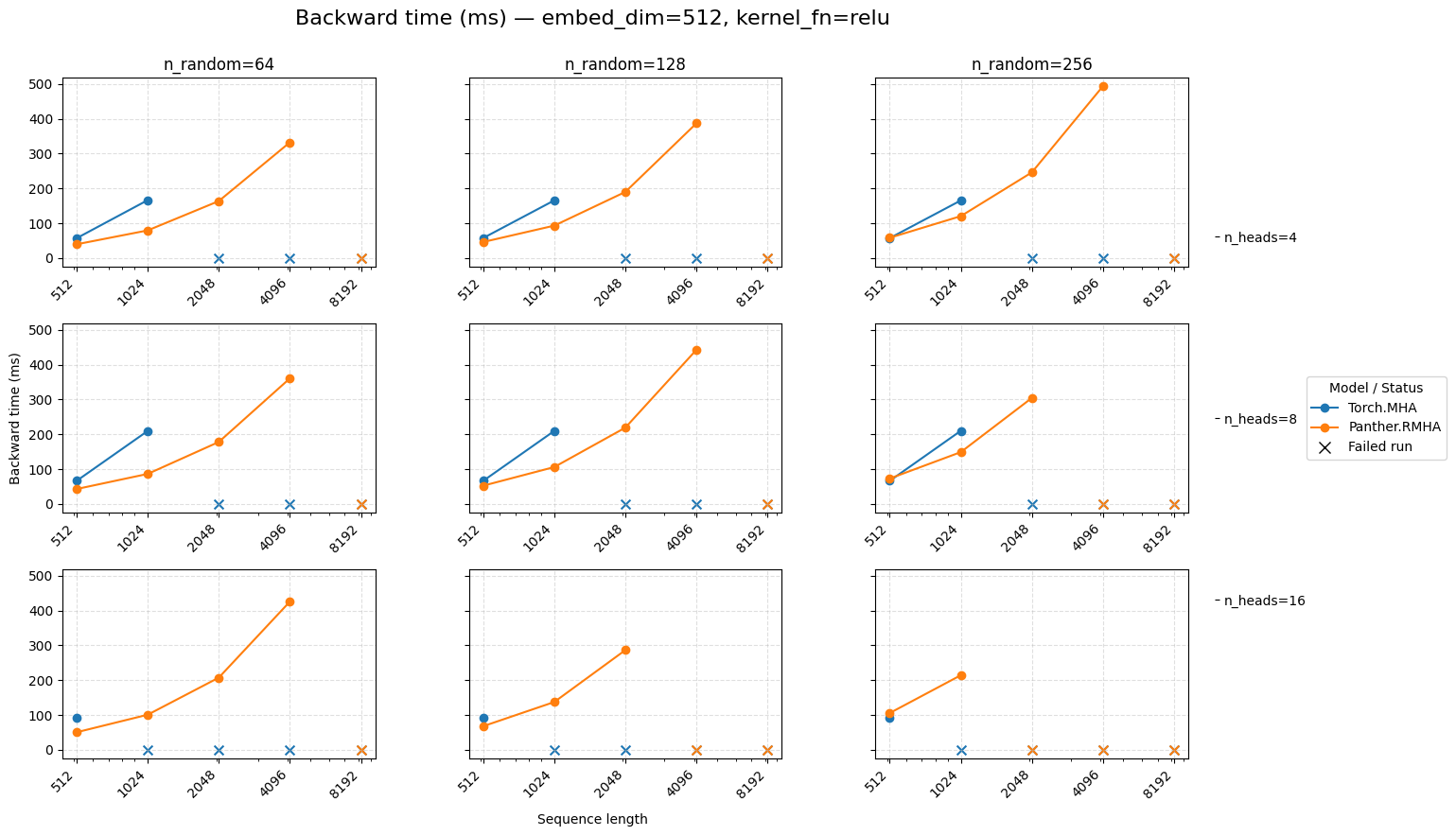
Backward time for attention embed=512 ReLU
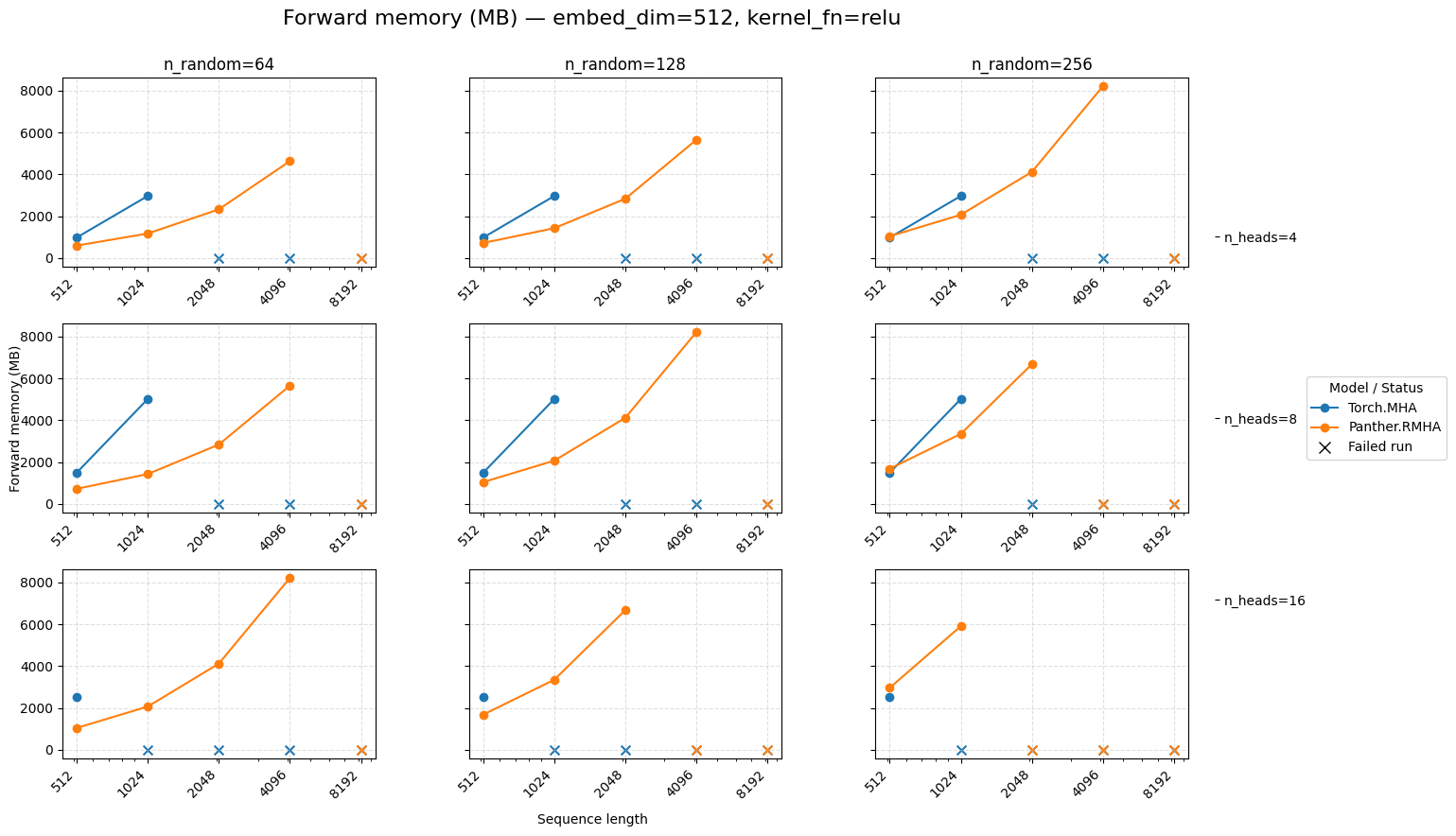
Forward memory for attention embed=512 ReLU
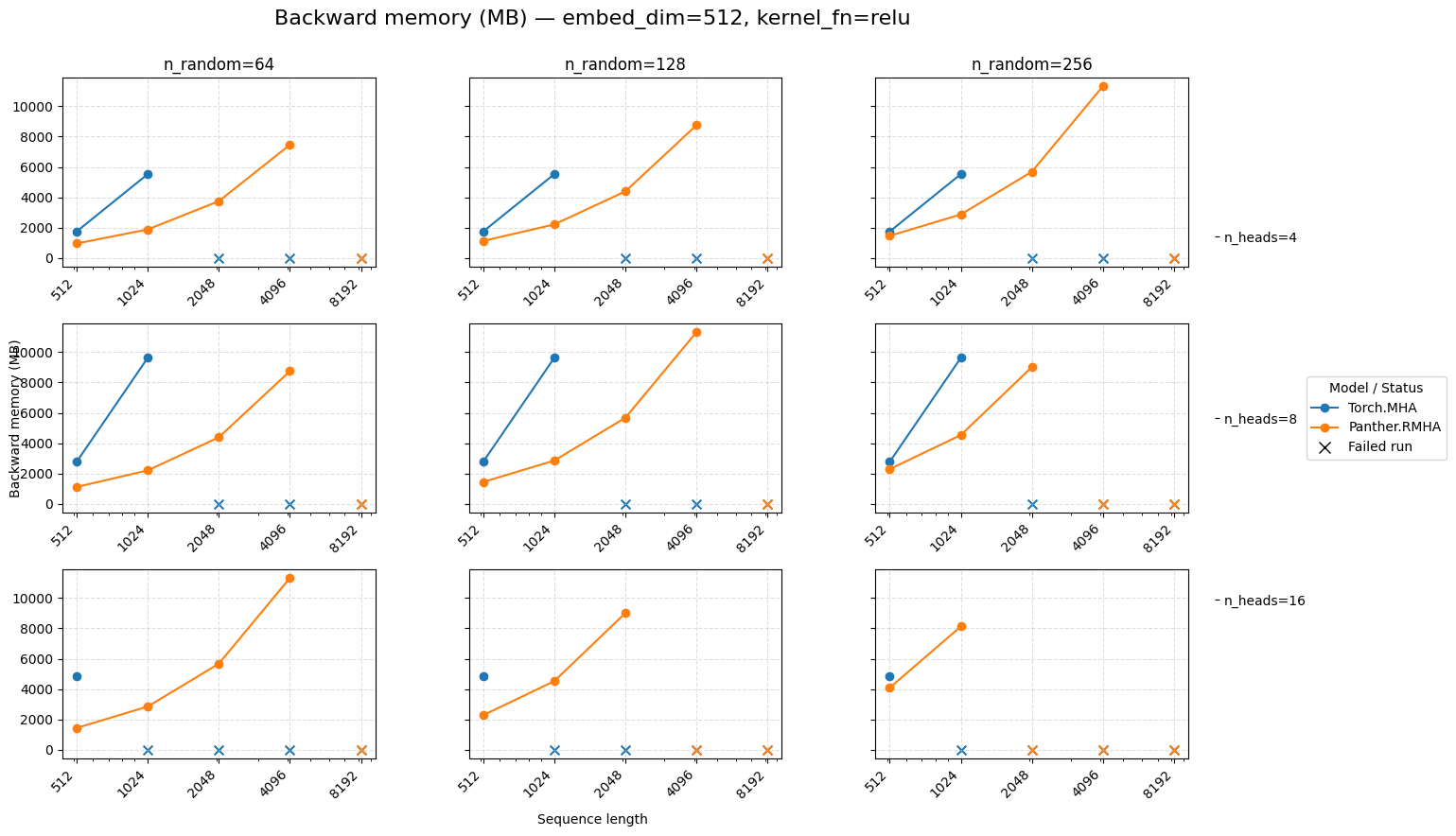
Backward memory for attention embed=512 ReLU
Embedding dimension 512 — Softmax activation#
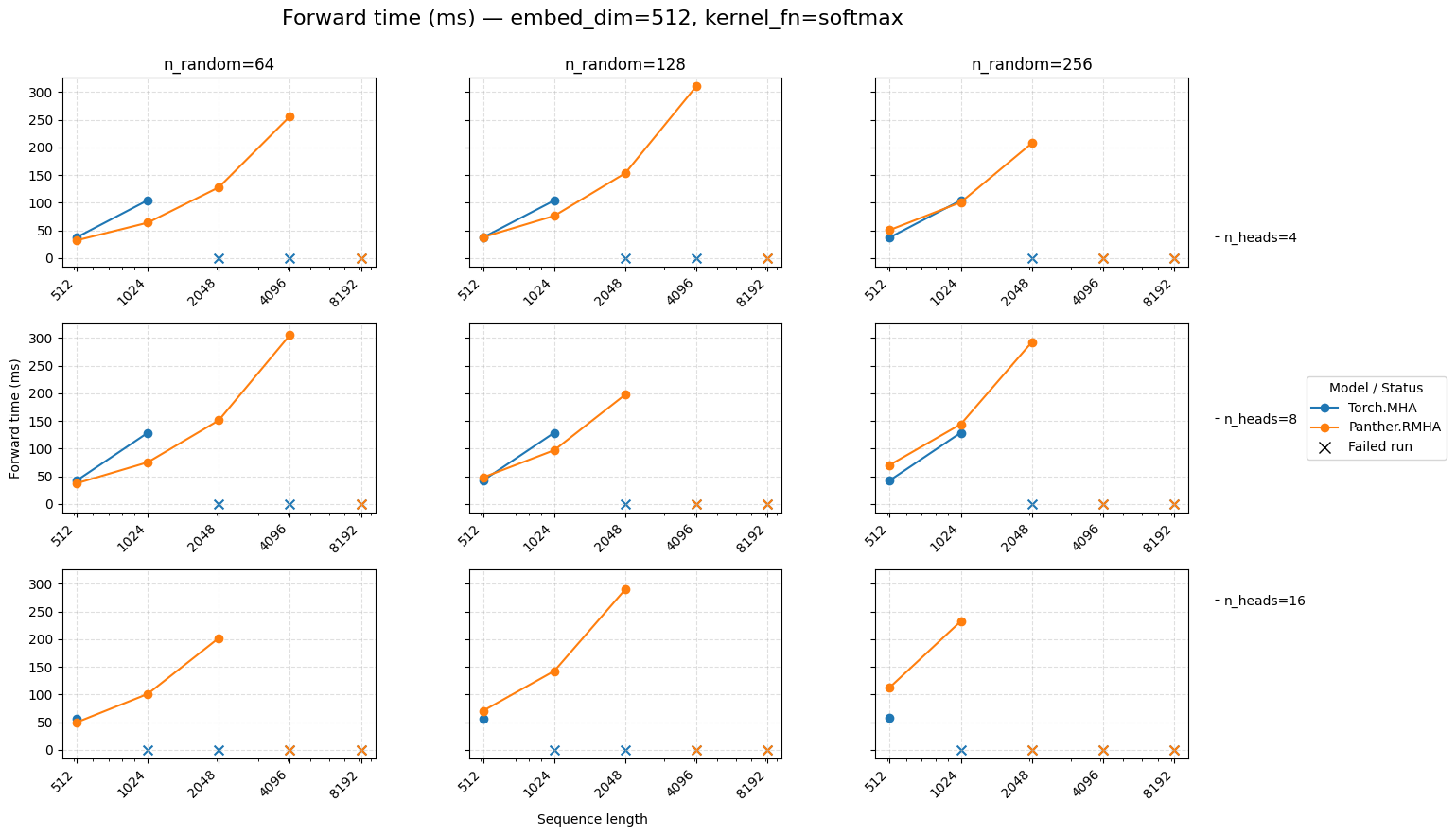
Forward time for attention embed=512 Softmax
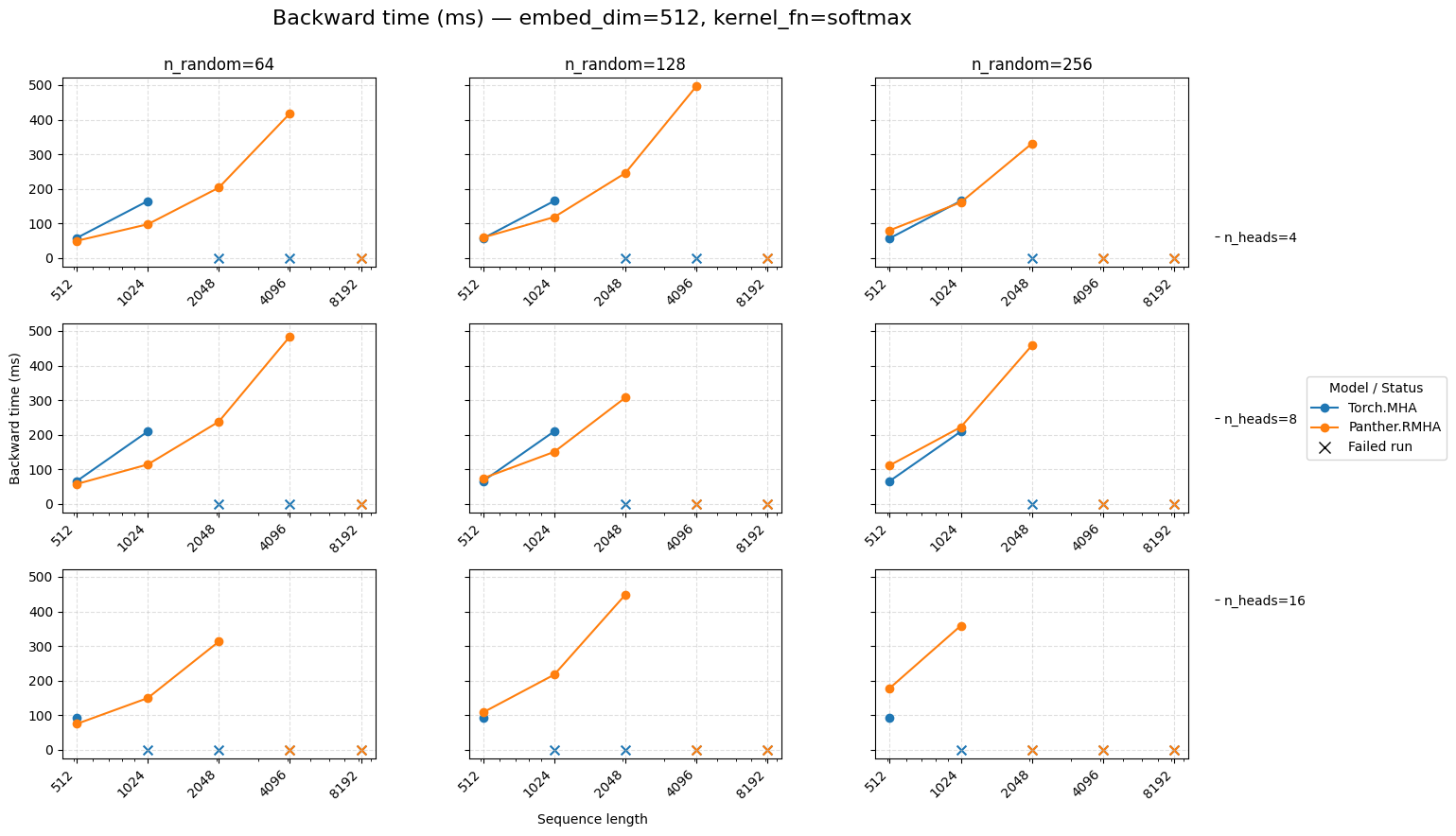
Backward time for attention embed=512 Softmax
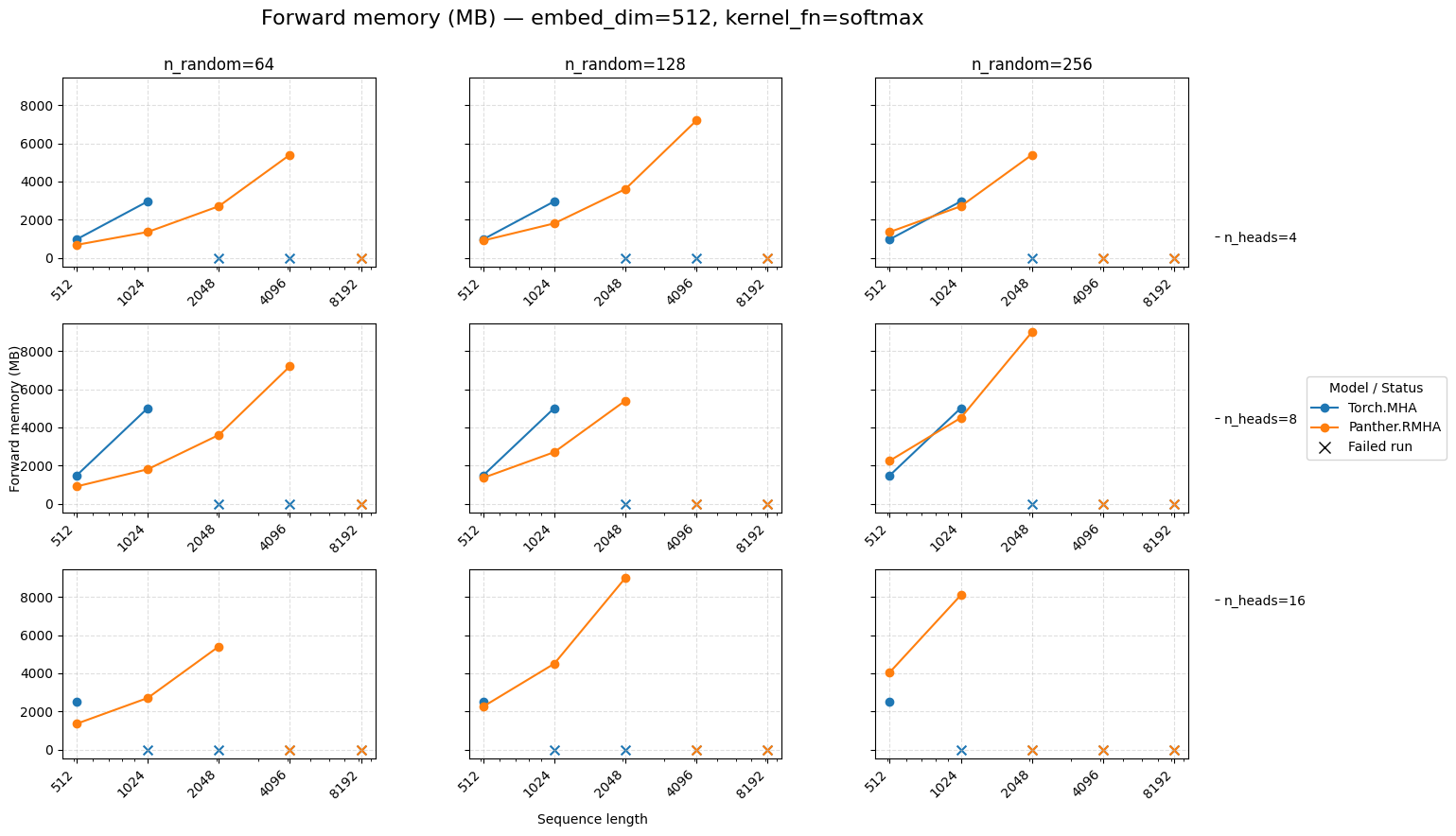
Forward memory for attention embed=512 Softmax
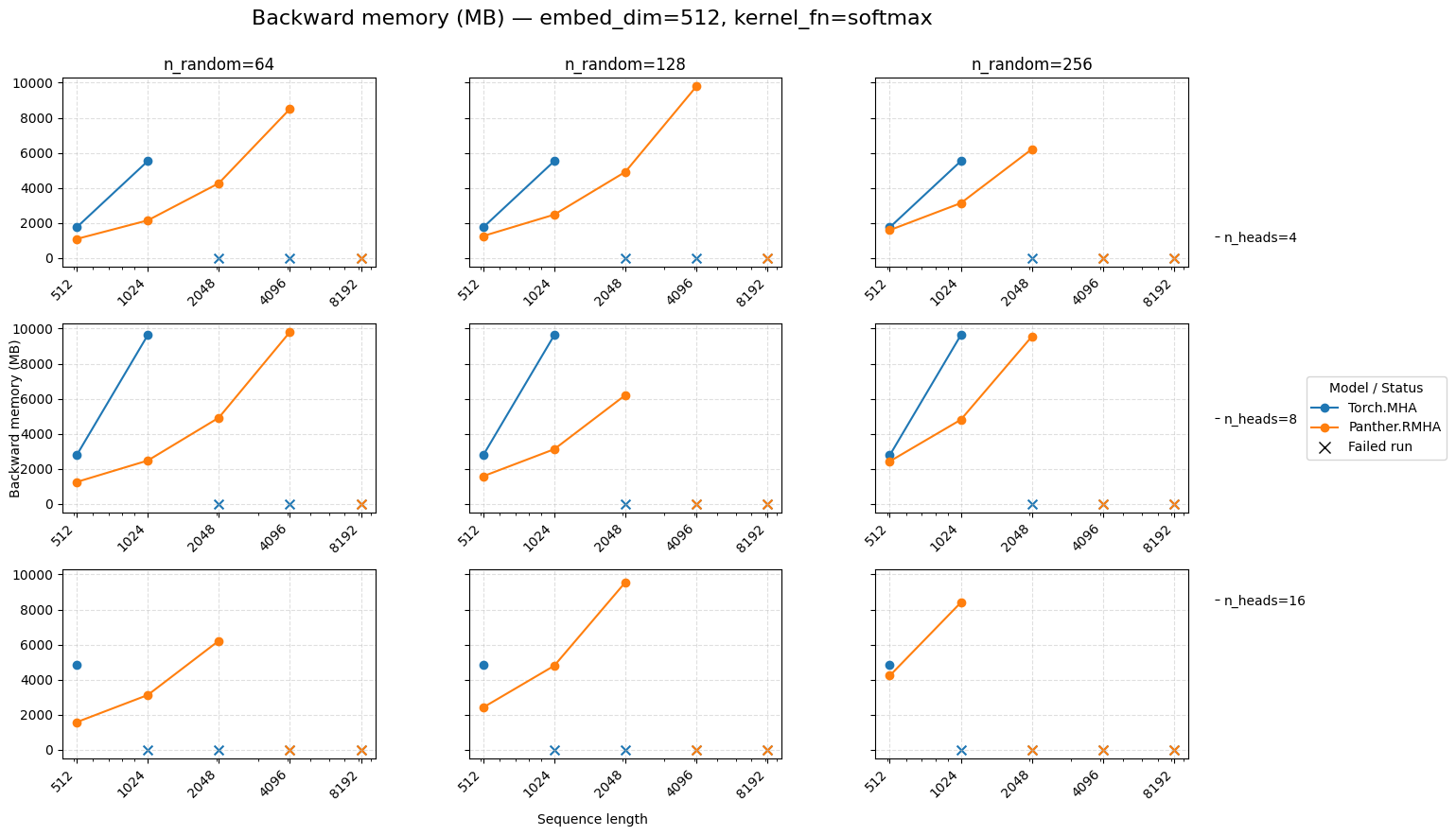
Backward memory for attention embed=512 Softmax
Embedding dimension 1024 — ReLU activation#
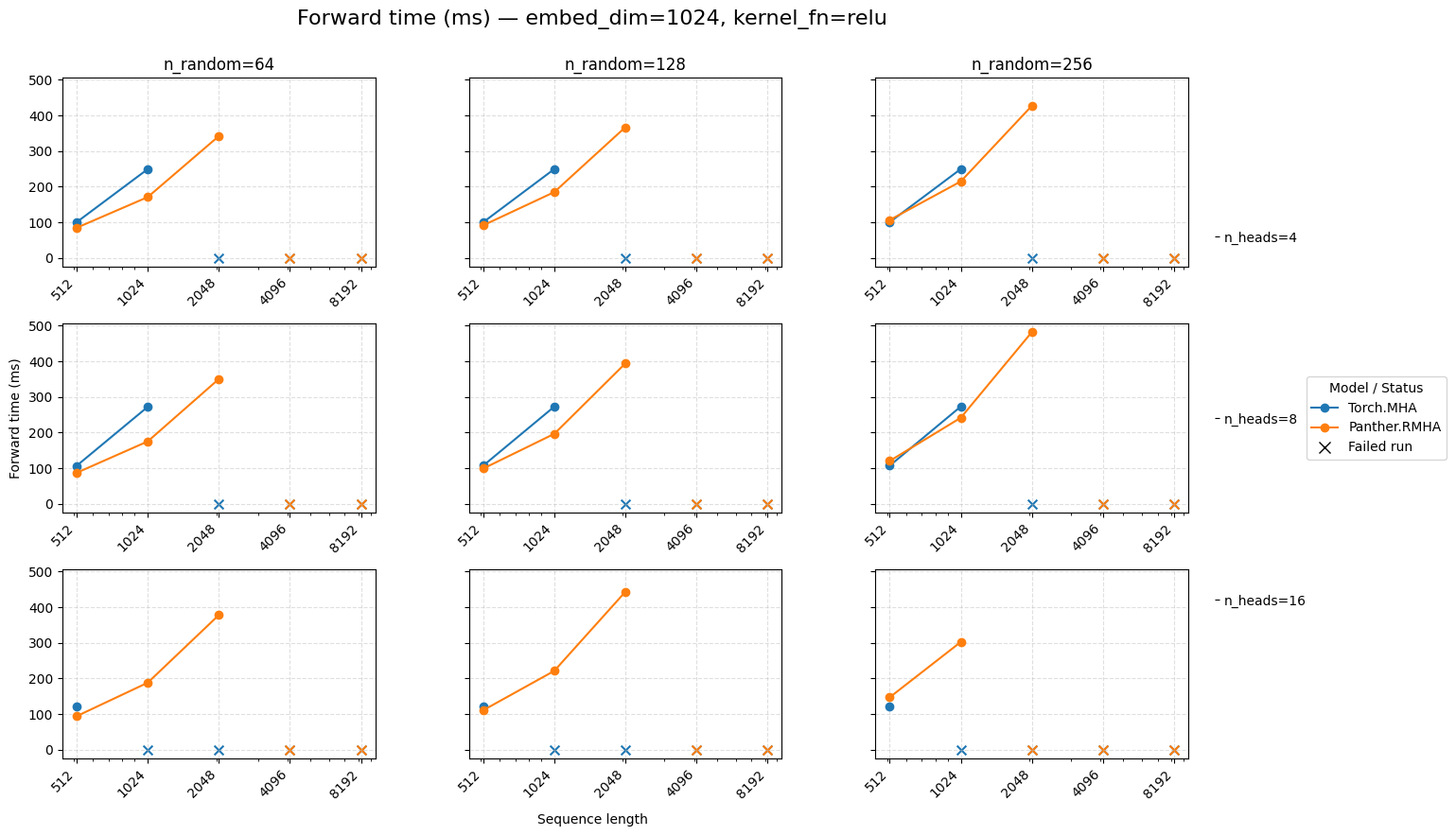
Forward time for attention embed=1024 ReLU
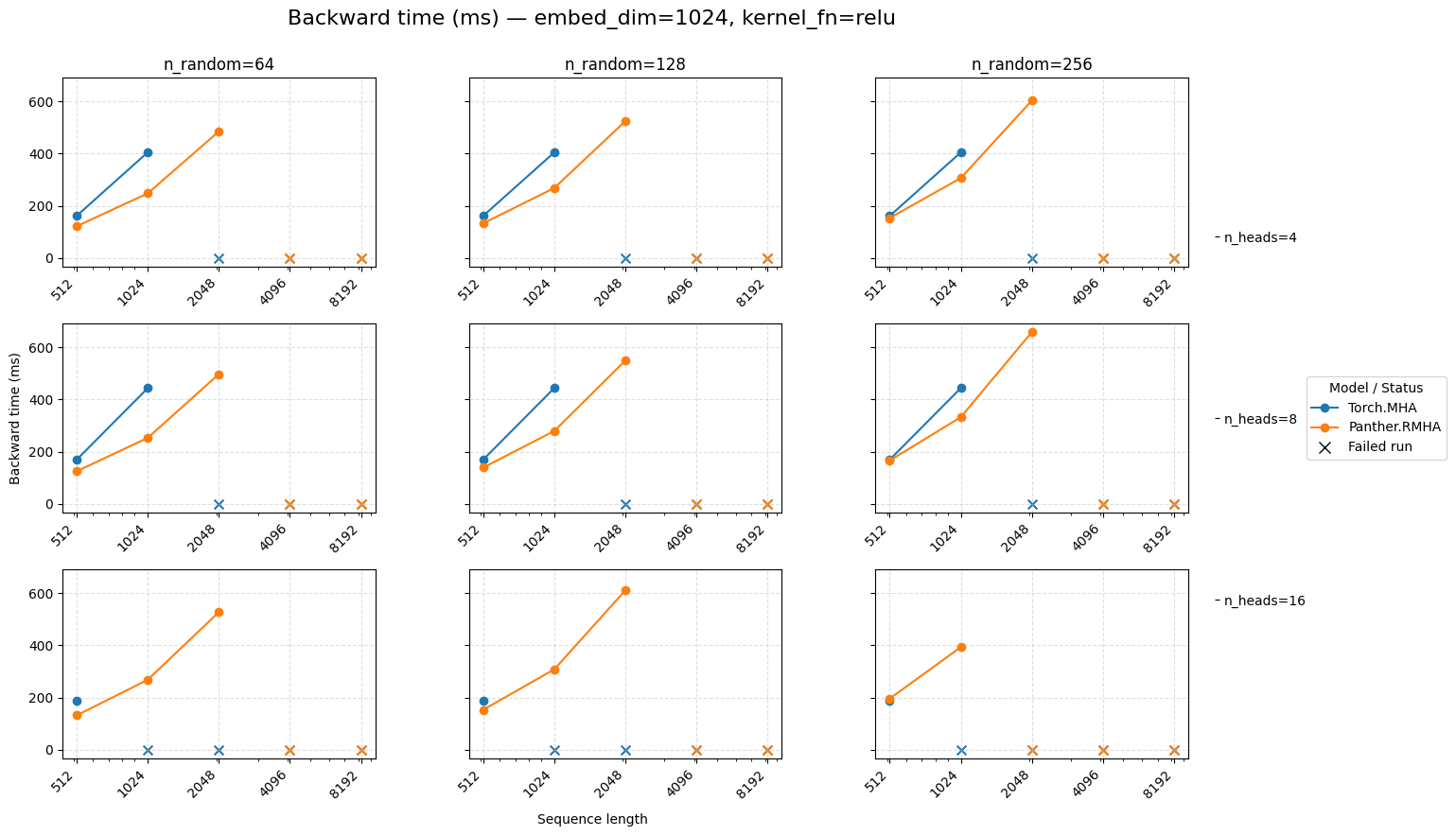
Backward time for attention embed=1024 ReLU
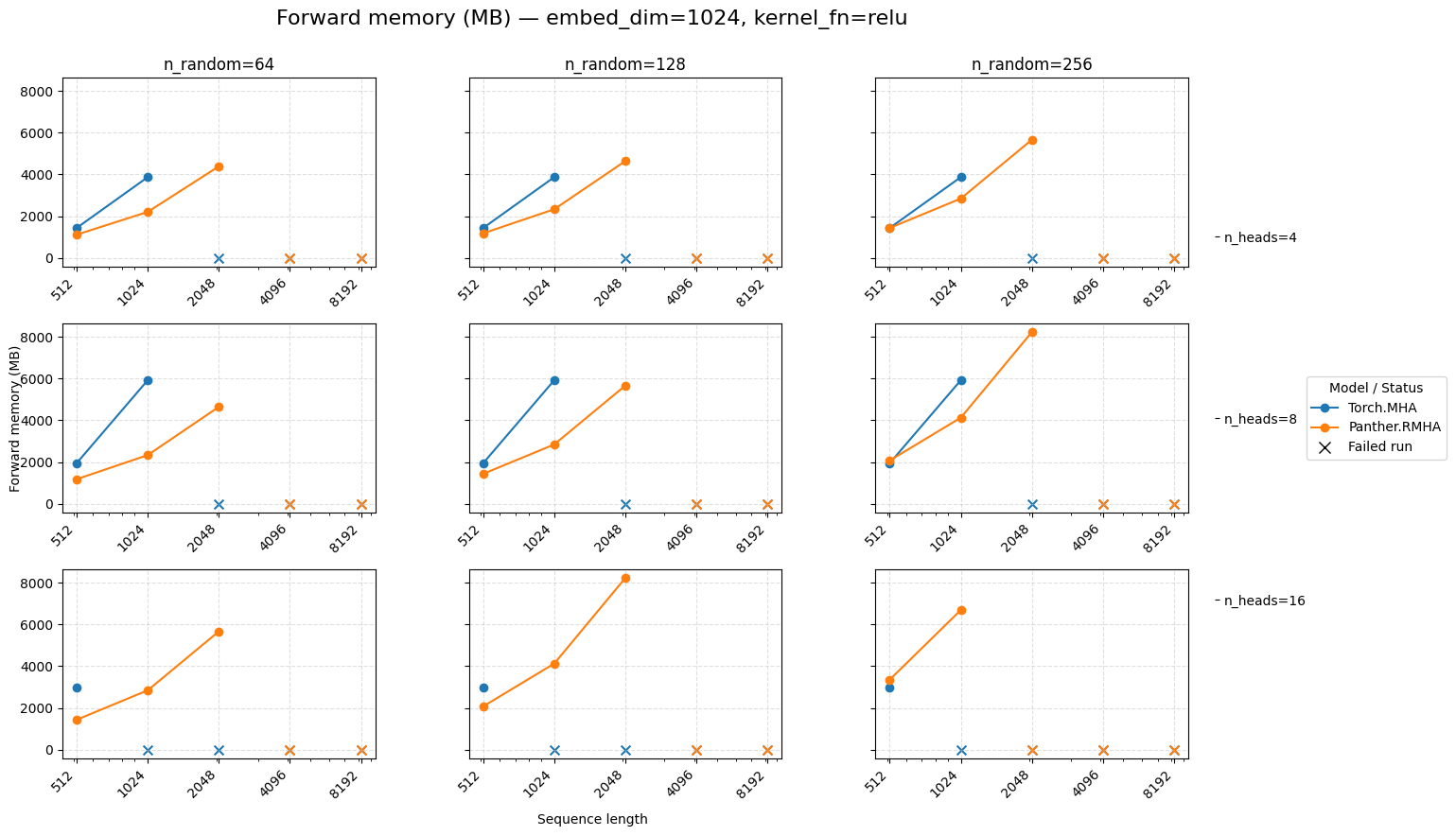
Forward memory for attention embed=1024 ReLU
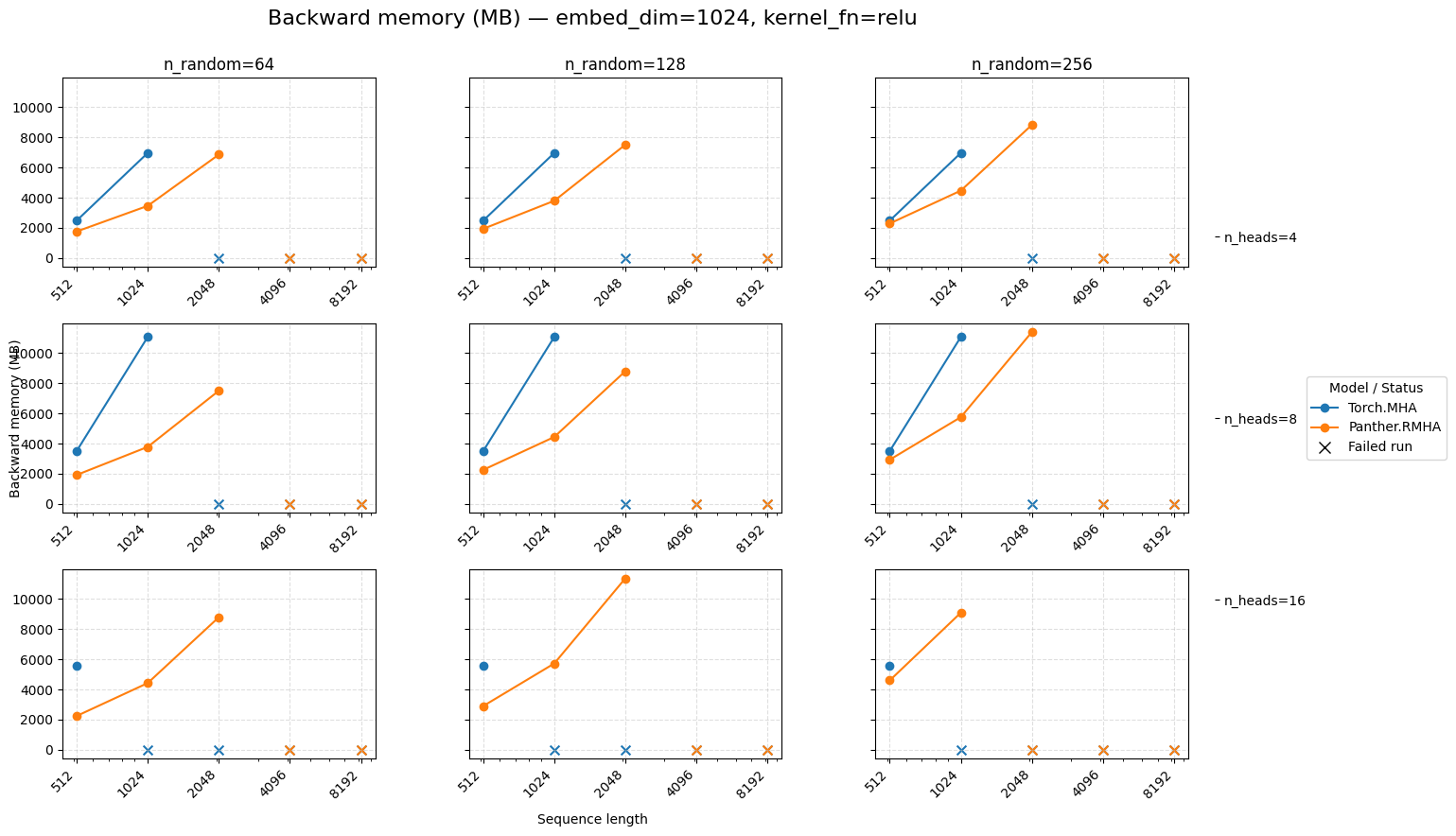
Backward memory for attention embed=1024 ReLU
Embedding dimension 1024 — Softmax activation#
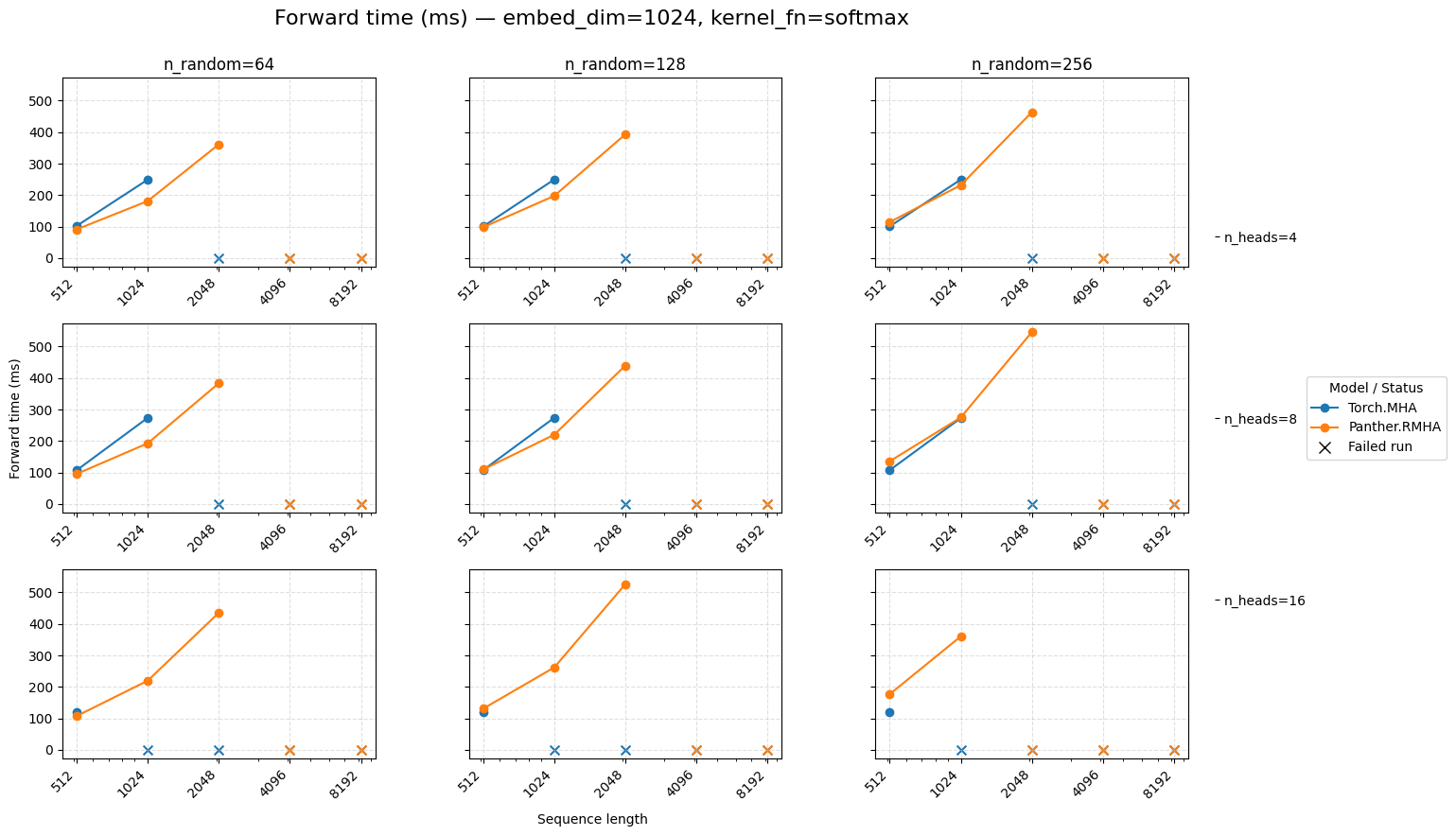
Forward time for attention embed=1024 Softmax
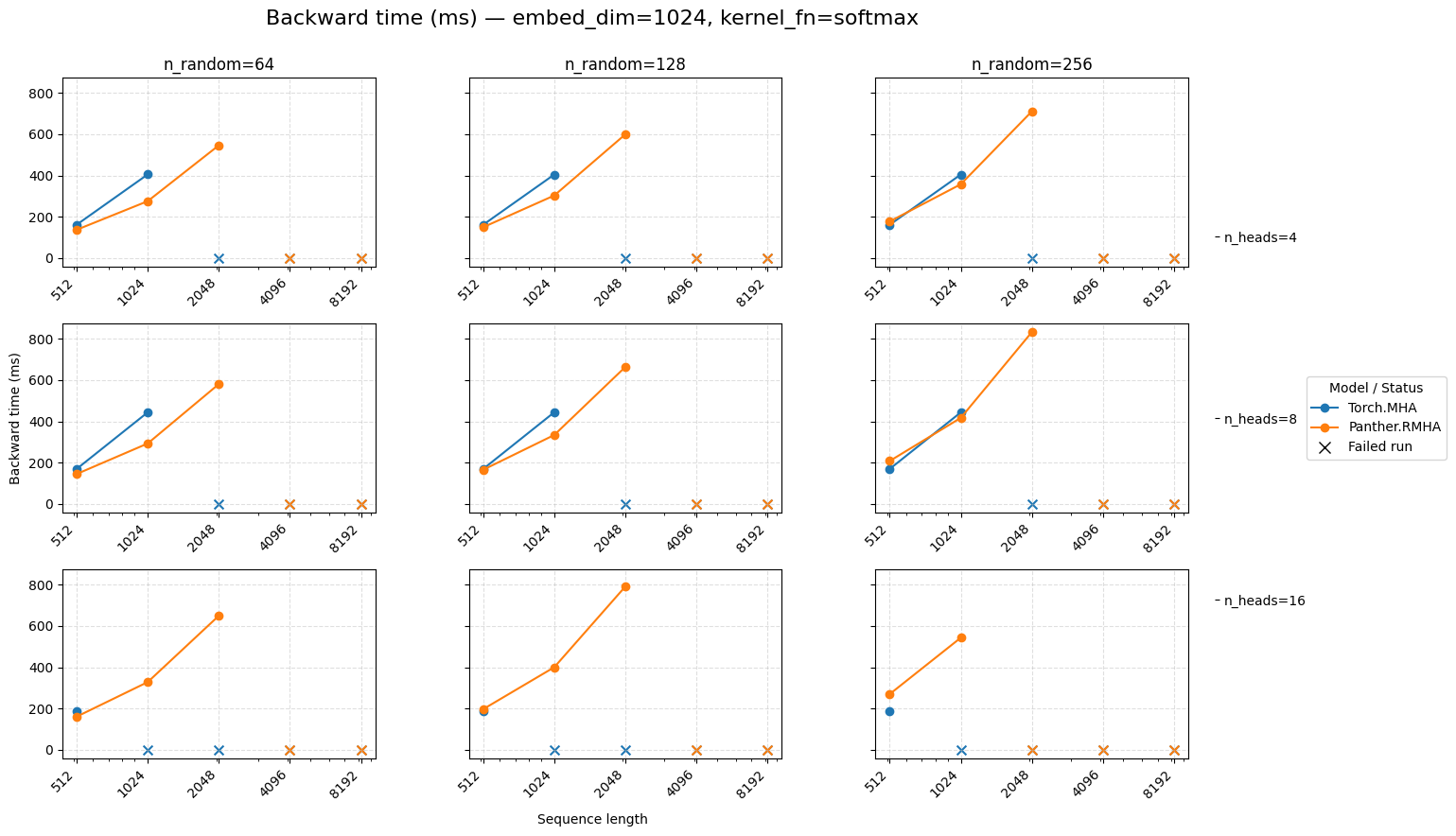
Backward time for attention embed=1024 Softmax
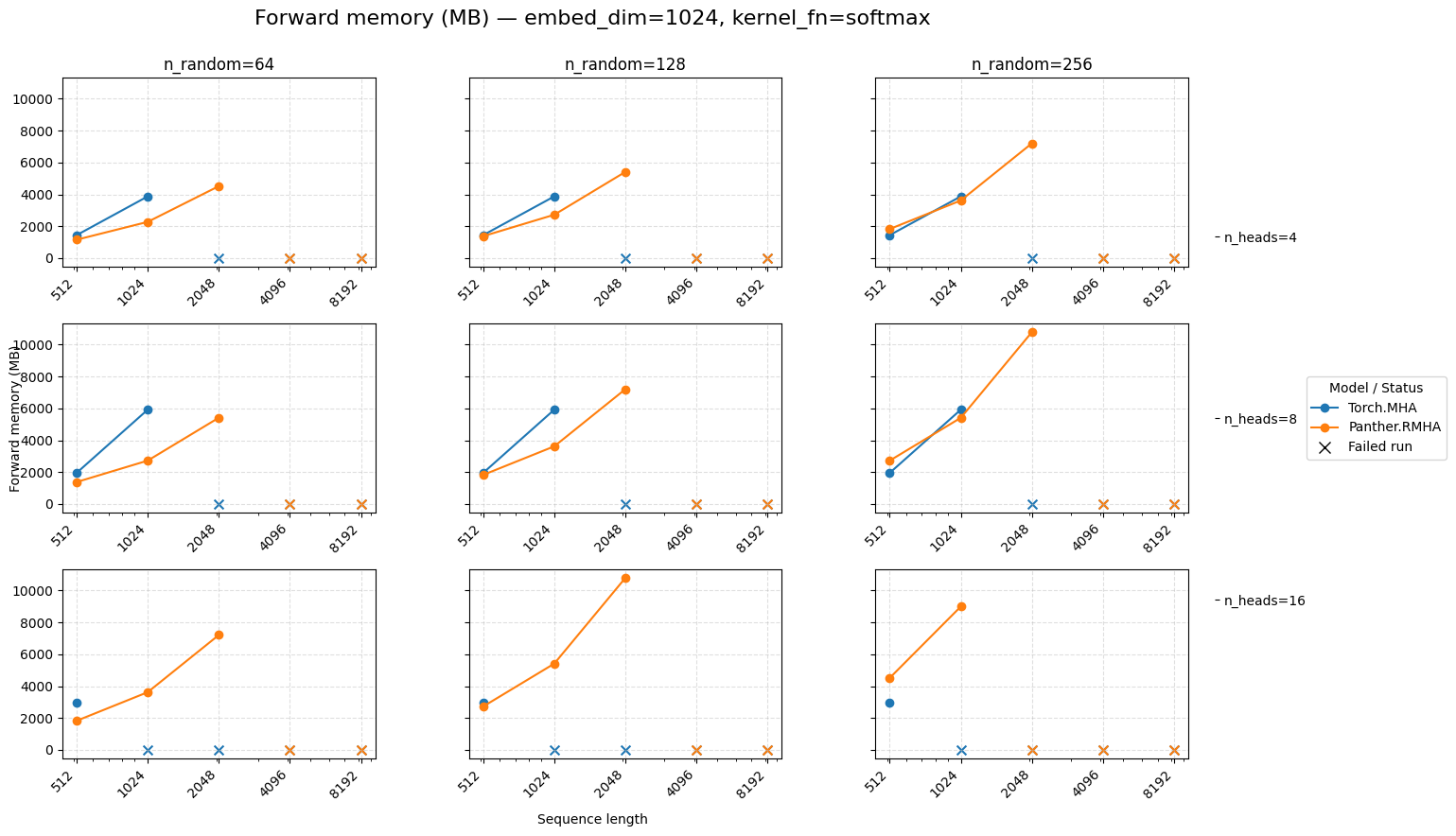
Forward memory for attention embed=1024 Softmax
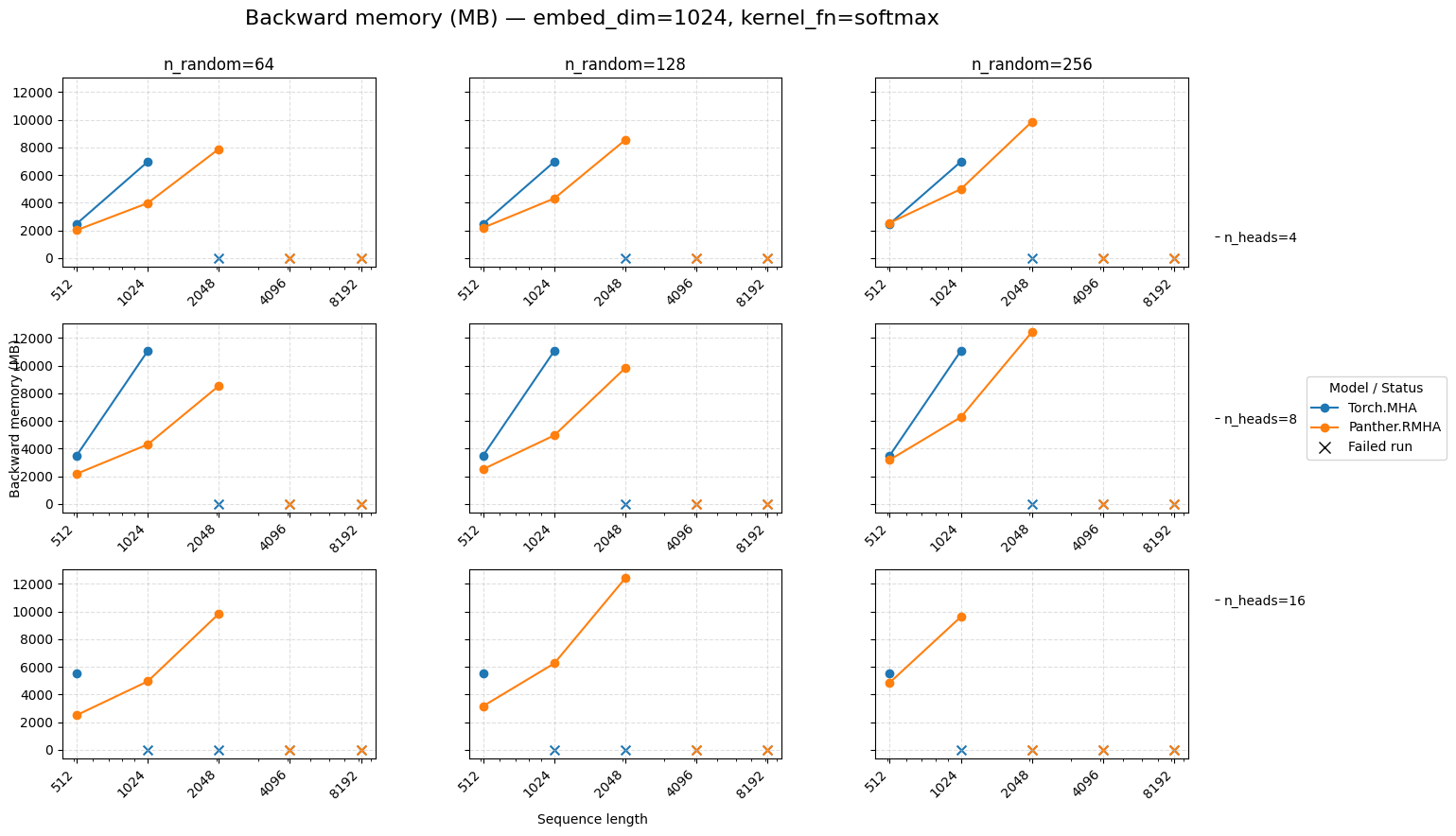
Backward memory for attention embed=1024 Softmax